
رقاقة واحدة تعادل صينية طعام – أكبر اكتتاب عام لرقاقة الذكاء الاصطناعي في التاريخ! خمسة خبراء مخضرمين في مجال الرقائق يراهنون على انفجار قوة الحوسبة للذكاء الاصطناعي لمدة عشر سنوات


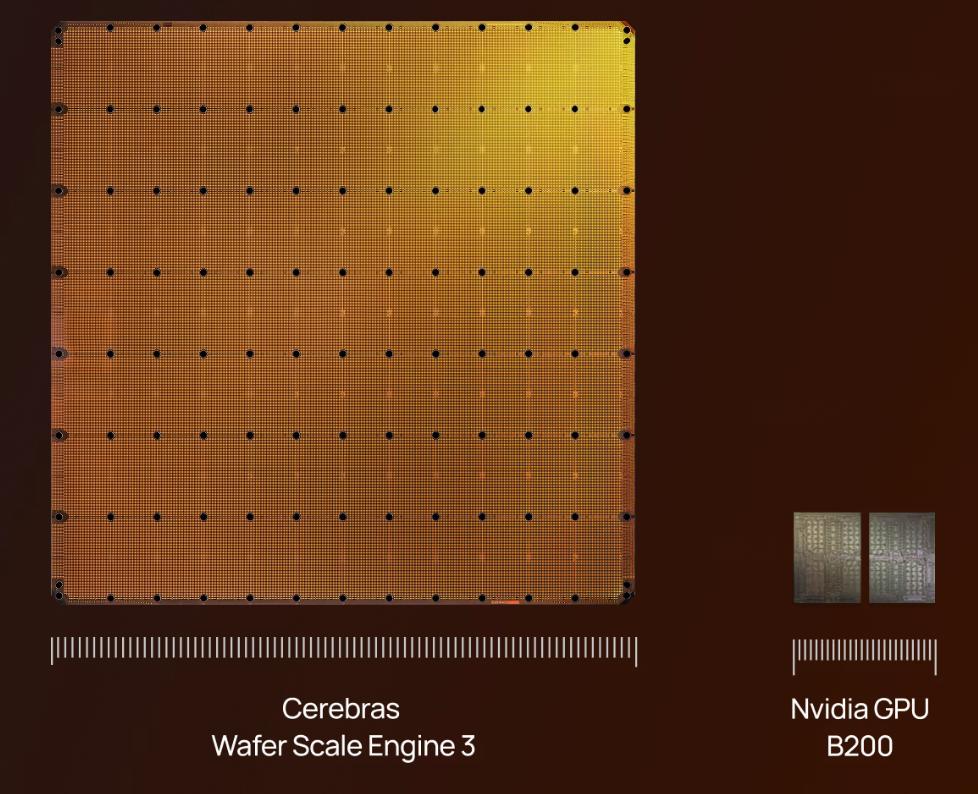
عادةً ما تكون رقاقات الحواسيب التي نراها بحجم ظفر الإصبع، أما الـ GPU فلا يتجاوز كف اليد، لكن شركة Cerebras من كاليفورنيا، الولايات المتحدة، صنعت شريحة بحجم صحن طعام كبير تقريباً، بقطر يتجاوز 200 ملم ومساحة تصل إلى 46,225 ملم مربع وتدمج 4 تريليون ترانزستور.
تم إدراج الشركة في بورصة ناسداك في 14 مايو 2026 بسعر إصدار 185 دولار، وسعر افتتاح 350 دولار، وارتفعت بنسبة 89٪ في اليوم الأول لتصل قيمتها السوقية إلى 75 مليار دولار. من بين خمسة مؤسسين مشاركين، أربعة منهم من شركة خوادم استحوذت عليها AMD تُدعى SeaMicro، والخامس من MIT. بدأوا العمل بهدوء منذ عام 2015 لما يقارب عشر سنوات، والآن ظهروا في مقدمة سباق قدرات الذكاء الاصطناعي مع شريحة بحجم الرقاقة الكاملة.

(المصدر: cerebras.ai)
المنتج الأساسي لشركة Cerebras يُدعى المحرك على مستوى الرقاقة الكاملة، وقد تطور حالياً إلى الجيل الثالث WSE-3. بينما تصنيع الرقائق التقليدية يقوم على تقطيع الرقاقة الواحدة إلى مئات الشرائح الصغيرة، سلكت Cerebras مساراً معاكساً فلم تقطعها، بل صنعت الشريحة الكاملة دفعة واحدة من رقاقة واحدة.هذه الرقاقة تدمج 84 شريحة افتراضية، كل شريحة فيها حوالي 10,700 نواة، ليصبح المجموع الكلي للمعالج 900 ألف نواة حسابية.
تتصل هذه النوى معاً عبر شبكة ثنائية الأبعاد على الرقاقة، وكل نواة مزودة بموجه بيانات ذو خمسة مخارج يدعم نقل البيانات في أربعة اتجاهات وعمليات القراءة والكتابة المحلية. يصل عرض نطاق الذاكرة إلى 21 بيتابايت في الثانية، وعرض نطاق الشبكة الداخلية إلى 214 بيتابايت في الثانية.

(المصدر: cerebras.ai)
تصنع شريحة WSE-3 بتقنية تايوان لصناعة أشباه الموصلات (TSMC) بدقة 5 نانومتر، وتبلغ مساحة كل نواة حسابية تقريباً 38,000 ميكرومتر مربع، نصفها عبارة عن SRAM محلي بسعة 48 كيلوبايت، والنصف الآخر عبارة عن دوائر منطقية. يصل إجمالي حجم الذاكرة SRAM في الشريحة بأكملها إلى 44 جيجابايت. جميع الذاكرة موزعة بجوار النوى، لذا فإن المسافة الفيزيائية بين الذاكرة ووحدة العمليات الحسابية تبلغ بضع عشرات من الميكرومتر، ولا توجد حاجة مثل الـ GPU التقليدي للوصول لذاكرة خارجية عالية عرض النطاق (HBM). تدعي شركة Cerebras أن عرض النطاق للذاكرة لديهم في نفس مساحة السليكون هو تقريباً 200 مرة أعلى من الـ GPU.

(المصدر: cerebras.ai)
هذا النوع من البنية ملائم جداً لمعالجة التبعثر غير الهيكلي في الشبكات العصبية، حيث أن الـ GPU التقليدي يجري العمليات الحسابية حتى لو كان الوزن يساوي 0، أما Cerebras فتقوم بتصفية الأصفار في المرسل ولا ترسل عبر الشبكة الداخلية سوى البيانات غير الصفرية إلى النوى الحسابية المقابلة.كل حزمة بيانات تتكون من 16 بت بيانات و16 بت معلومات تحكم، وعند استلام البيانات، يتم تفعيل عملية الضرب والجمع تلقائياً. هذة الطريقة تتجنب الكثير من الحسابات غير المجدية وتحقق تسريعاً ملحوظاً في النماذج ذات التبعثر العالي.
تشير الورقة البيضاء التقنية للشركة إلى أنه في العمليات الحسابية تحت مستوى BLAS للمضاعفات المصفوفية العامة (مثل ضرب مصفوفة بمتحول أو متحول بسكالار)، عادةً ما تكون الشرائح التقليدية محدودة بعرض نطاق الذاكرة وغير قادرة على العمل بكامل الطاقة، لكن بنية Cerebras نظراً لعرض النطاق العالي للذاكرة تمكنها من الحفاظ على معدل استخدام مرتفع.
(المصدر: cerebras.ai)
التقنية الجوهرية الأخرى لدى Cerebras هي Weight Streaming، حيث لا يتم تخزين أوزان النماذج الكبيرة أثناء التدريب على الشريحة، بل توضع في جهاز خارجي يسمى MemoryX وتنقل إلى شريحة WSE-3 حسب الحاجة بشكل تدفق مستمر. وعند حساب كل طبقة من الشبكة، يتم قراءة الأوزان من DRAM وذاكرة الفلاش الخارجية ثم إدخالها إلى النوى الحسابية عبر واجهات الدخل والخرج للشريحة.
عند وصول كل وزن إلى النواة، يتم ضربه مع قيم التفعيل المحلية بالجملة، وبعد الانتهاء من الحساب يتم التخلص من الوزن فوراً ولا يبقى على الشريحة. هذه الطريقة تجعل حجم النموذج غير مقيد بسعة ذاكرة الشريحة، ويمكنها دعم نماذج فائقة الكبر تصل إلى تريليونات من المعاملات.

(المصدر: cerebras.ai)
على مستوى البرمجيات، توفر Cerebras سلسلة أدوات كاملة للترجمة، حيث يمكن تلقائياً تحويل النماذج المكتوبة بـ PyTorch أو TensorFlow إلى 900 ألف نواة. بالنسبة للنماذج من نوع Transformer، تمتلك عناصر التفعيل ثلاث أبعاد: حجم الدفعة، طول السلسلة، والبعد المُخفي. ويقوم المترجم بتقسيم البعد المُخفي على الاتجاه X للشريحة، بينما يقسم كل من حجم الدفعة وطول السلسلة على الاتجاه Y.
عند حساب عمليات ضرب المصفوفات، يتم بث الأوزان عبر الصفوف إلى جميع النوى في الأعمدة المقابلة وتفعيل عملية الضرب والجمع، ثم تقليل جزء من النتائج على الاتجاه العمودي، وأخيراً توزيع النتائج على الشريحة استعداداً لحساب الطبقة التالية. يتم جدولة جميع العمليات بشكل ثابت، حيث يتم تحميل الأوامر مرة واحدة قبل التنفيذ ولا يتم تغييرها أثناء التنفيذ.

(المصدر: cerebras.ai)
يتمتع جميع المؤسسين المشاركين الخمسة لشركة Cerebras بخلفية قوية في هندسة الرقائق والأنظمة.
الرئيس التنفيذي Andrew Feldman حاصل على شهادة من جامعة ستانفورد، وأسّس سابقاً شركة سيرفرات صغيرة تم الاستحواذ عليها من قبل AMD بمبلغ 357 مليون دولار.
كبير التقنيين Sean Lie حاصل على بكالوريوس وماجستير في الهندسة الإلكترونية وعلوم الحاسب من معهد MIT، وعمل كمهندس لهندسة المحاكاة الافتراضية في SeaMicro، وأصبح زميل AMD بعد الاستحواذ.
مهندس البنية النظامية Jean-Philippe Fricker حاصل على شهادة ماجستير من المعهد الفدرالي السويسري للتكنولوجيا في لوزان، وعمل في DSSD وSeaMicro وألكاتيل لوسنت وRiverstone Networks في وظيفة مهندس معماريات عتادية.
كبير مهندسي التقنيات المتقدمة Michael James يحمل ثلاث درجات علمية من جامعة كاليفورنيا في بيركلي في البيولوجيا العصبية الجزيئية والرياضيات وعلوم الحاسوب، وكان مسؤولاً عن البرمجيات الموزعة في SeaMicro.
كبير التقنيين الشرفي المتقاعد Gary Lauterbach يمتلك أكثر من 50 براءة اختراع، وكان مهندساً متميزاً في Sun Microsystems وقاد تصميم معمارية معالجات UltraSPARC III و UltraSPARC IV.
تعتمد نموذج عمل Cerebras على بيع أنظمة CS-3 الكاملة، والتي تم تصميمها حول شريحة WSE-3 ويمكن تركيبها على الرفوف القياسية لمراكز البيانات. العملاء الأساسيون هم مؤسسات بحثية وشركات كبرى، بما في ذلك شركة الذكاء الاصطناعي الإماراتية G42 وجامعة محمد بن زايد للذكاء الاصطناعي. بحسب وثائق الإفصاح لعملية الطرح، بلغت إيرادات Cerebras لعام 2025 حوالي 510 مليون دولار، ساهمت G42 بنسبة 24% وMBZUAI بنسبة 62%. وبلغ صافي الربح السنوي للشركة 238 مليون دولار، بعد أن كانت في السنة السابقة بخسارة 482 مليون دولار.
كانت Cerebras قد حاولت الإدراج في 2024، لكنها اعتمدت آنذاك بشكل كبير على عميل واحد وهو G42 الذي مثل 87% من الإيرادات. ونظراً لأن الصفقات مع جهات إماراتية تتطلب مراجعة من لجنة الاستثمار الأجنبي الأمريكية، رغم الموافقة النهائية لاحقاً إلا أن Cerebras سحبت الطلب حينها. وفي الجولة الأخيرة من الإدراج، تحسنت درجة تركيز العملاء حيث انخفضت حصة أكبر عميل MBZUAI إلى 62%، إلا أن أكبر عميلين ما زالا يمثلان 86% من الإيرادات، ولا تزال مخاطر التركيز موجودة.
تمتاز Cerebras في مجال رقاقات الذكاء الاصطناعي بمسار تقني فريد. إذ أن معظم المنافسين يقلدون بنية الـ GPU باستخدام عدد ضخم من الأنوية الصغيرة مع ذاكرة HBM، أما Cerebras فاختارت معالجة المشكلة عبر شريحة رقاقة كاملة ضخمة. هذا الحل يمنحها أفضلية واضحة في العمليات المتناثرة وفي استنتاج النماذج الكبرى، غير أن تكاليف التصنيع ونسب النجاح في الإنتاج تشكل تحديات ليست بالسهلة.
يكمن التحدي في أنه إذا حدث خلل قاتل في أي جزء من الرقاقة الكاملة فقد يؤثر على الشريحة كلها؛ وقد عالجت Cerebras الأمر بإدخال روابط زائدة وآليات تصحيح ذاتي في التصميم. كما أن استهلاك الطاقة وتبديد الحرارة في الشرائح بحجم الرقاقة من التحديات الهندسية، وصممت CS-3 خصيصاً نظام تبريد سائل لهذه الغاية.
مع اقتراب شركات الذكاء الاصطناعي مثل OpenAI وAnthropic وSpaceX من الإدراج، أصبحت سباقات شرائح الذكاء الاصطناعي نقطة اهتمام في سوق رأس المال. ويُعتبر صعود Cerebras كأول سهم رقاقات ذكاء اصطناعي نقي يُدرج في ناسداك وارتفاع السهم بنسبة 89% في اليوم الأول إشارة إيجابية لباقي الشركات في المجال.
ومع ذلك، تتزايد حدة المنافسة في سوق رقاقات الذكاء الاصطناعي، فإلى جانب Nvidia تطرح AMD وIntel وعدة شركات ناشئة منتجات جديدة أيضاً. وهل ستثبت Cerebras من خلال شريحتها على مستوى الرقاقة الكاملة مكانتها في سوق التدريب الرئيسي للذكاء الاصطناعي؟ سيحتاج ذلك إلى جذب المزيد من العملاء ووقت أطول لتأكيده.
إخلاء المسؤولية: يعكس محتوى هذه المقالة رأي المؤلف فقط ولا يمثل المنصة بأي صفة. لا يُقصد من هذه المقالة أن تكون بمثابة مرجع لاتخاذ قرارات الاستثمار.
You may also like
تقلب PEAQ بنسبة 54.6٪ خلال 24 ساعة: ارتفاع حجم التداول ودعم الشراكة مع CoinList في "الإصدار الأولي للآلات"
تقلب IAG (Iagon) بنسبة 44.2% خلال 24 ساعة: ارتفاع حجم التداول يؤدي إلى ضخ سريع ثم تصحيح حاد