
Analisi approfondita di Cerebras: inferenza a livello di wafer, ordini OpenAI e le probabilità della potenza di calcolo non-Nvidia


Indice
- Riepilogo delle opinioni
- I. Metti Cerebras al posto giusto: non vende chip, vende bassa latenza
- II. Gli ordini sono reali, ma non senza un costo
- III. La collaborazione con AWS verifica il modello di business più di OpenAI
- IV. Valutazione: 125 dollari e 160 dollari sono due storie diverse
- V. Il suo significato per la filiera: TSMC, AWS e Nvidia non sono perdenti
- VI. Opinione contraria: perché potrebbe essere un titolo difficile da detenere
- VII. Conclusione personale: osserva, aspetta, non considerare la scarsità un margine di sicurezza
Cerebras approfondito: inferenza a livello di wafer, ordini OpenAI e scommessa sul calcolo non Nvidia
404K Semi-AI | Rapporto di ricerca approfondito sugli investimenti
Riepilogo delle opinioni
Il giudizio chiave di questo articolo è molto semplice:Cerebras non è un sostituto diretto di Nvidia, ma è l'opzione più pura di capacità di calcolo non Nvidia dopo che l'inferenza AI è passata dalla "competizione sulla capacità di throughput" alla "bassa latenza, output lungo, interazione in tempo reale". Se nei prossimi tre anni il campo principale dell’AI resta cluster di training, piattaforme GPU generiche e l’ecosistema CUDA, Cerebras sarà un’azienda hardware di nicchia ad alta valutazione; ma se i carichi di lavoro di valore reale passano dalla generazione offline ad agenti in tempo reale, codice interattivo, inferenza a catena lunga e workflow aziendali, la sua strategia a livello di wafer improvvisamente diventa preziosa.
Non sto dicendo che “Cerebras batterà Nvidia”, ma:il suo successo dipende dall’apertura contemporanea di due porte: primo, OpenAI e AWS trasformano la bassa latenza dell’inferenza in una domanda di produzione; secondo, Cerebras riesce a consegnare i contratti nonostante i vincoli di capacità TSMC, costruzione data center, margine lordo e concentrazione della clientela. Non è una crescita lineare tipica delle aziende semiconduttori, ma un’opzione infrastrutturale accesa da contratti OpenAI, verificata dal canale AWS e la valutazione IPO decide la scommessa.
Se guardiamo il range IPO originale di 115-125 dollari, Cerebras è più simile ad un asset raro ad “alto rischio ma payout ancora decente”; se il prezzo di mercato di 150-160 dollari si conferma, il payout verrebbe chiaramente compresso, a meno che gli investitori credano che i 750MW di OpenAI siano solo la prima fase e che AWS Bedrock trasformerà Cerebras nel cloud inferenziale in tempo reale de facto.

Il quadro ripreso qui sopra si può applicare anche a Cerebras: la catena del calcolo AI non si basa più solo sul prezzo delle GPU, ma ciò non significa che tutti i chip non Nvidia vinceranno. Il vero mercato da rivalutare è la "migrazione del collo di bottiglia": il bottleneck dell'era training sono GPU, HBM, NVLink e la potenza del data center; quelli nuovi dell'era inferenziale sono latenza, bandwidth, efficienza di decodifica, distribuzione cloud e costo per token. Cerebras si trova esattamente a questo punto di migrazione.
I. Metti Cerebras al posto giusto: non vende chip, vende bassa latenza
La cosa più memorabile del sito ufficiale di Cerebras è la specifica estrema del WSE-3: 46.225 mm2, 4 trilioni di transistor, 900.000 core AI ottimizzati, 125 PFLOPS di capacità AI massima. Questo dato è impressionante, ma il significato vero per gli investimenti non è “grande”, bensì “porta la comunicazione dentro il chip”. Nei cluster GPU tradizionali per l’inferenza di grande modelli, molti costi non vengono dalla capacità di calcolo, ma dall’accesso alla memoria, dalla comunicazione tra chip, dallo scheduling instabile e dalla generazione sequenziale del token output. La strategia a livello di wafer di Cerebras si basa sul fatto che, quando il modello diventa abbastanza intelligente, la differenza di esperienza per cui l’utente è disposto a pagare si sposta dall’“accuratezza della risposta” alla “tempestività della risposta.”
"La capacità entrerà online in diverse tranche fino al 2028."
Questa breve frase sul sito OpenAI è più importante di molte slogan. I 750MW non sono un acquisto hardware una tantum, ma capacità a bassa latenza inserita a lotti nello stack inferenziale di OpenAI. Ovvero, la verifica commerciale di Cerebras non è vendere qualche macchina ad un laboratorio, ma entrare nel sistema produttivo di un prodotto AI ad alto volume reale. Se OpenAI farà della codifica realtime, degli agenti, dell’output lungo e delle interazioni iterative le funzioni core, la capacità inferenziale a bassa latenza non sarà un “nice to have”, ma la base dell’esperienza.
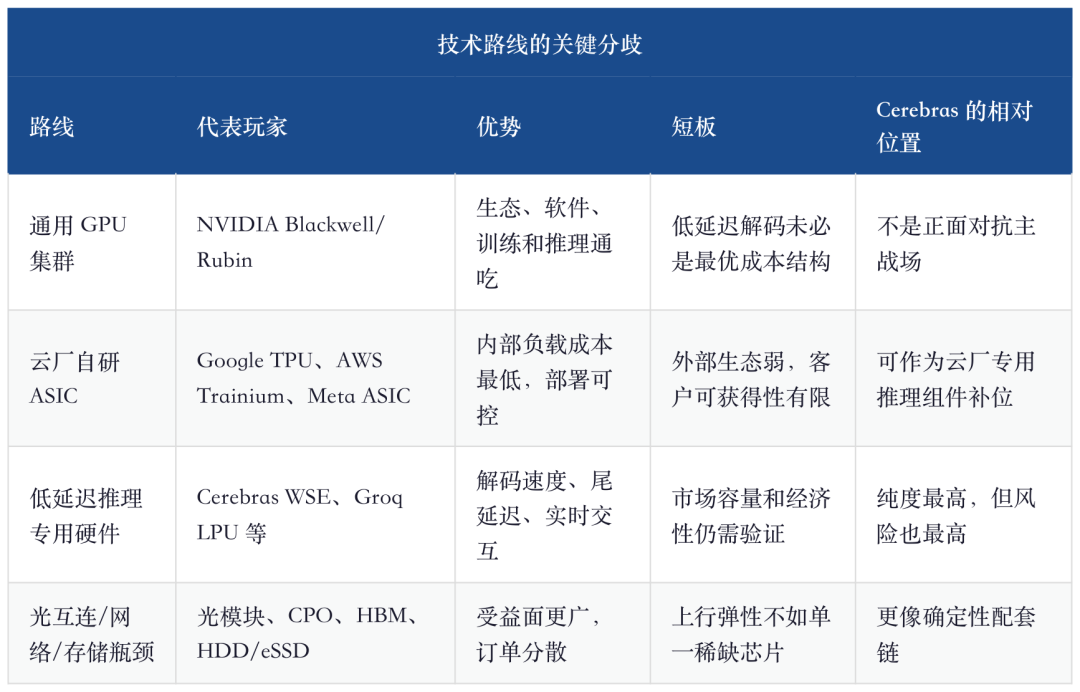
Il confronto tra architetture SRAM di SemiVision offre un ottimo background tecnico: la fase prefill si presta al calcolo parallelo, la fase di decoding invece è altamente sequenziale e dipende fortemente dal token precedente, risultando sensibilissima a bandwidth e latenza di memoria. La collaborazione tra AWS e Cerebras commercializza proprio questa logica: Trainium gestisce il prefill, Cerebras CS-3 gestisce il decode, connessi dalla rete EFA. Questa struttura non è solo marketing, ma indica che le cloud vendor hanno iniziato a scomporre l’inferenza in moduli fisici di calcolo.
"Il decode rappresenta tipicamente la maggior parte del tempo di inferenza."
Questa frase spiega perché Cerebras ha acquisito visibilità nell’era inferenziale. Sul mercato del training, Cerebras può difficilmente scuotere l’ecosistema software di Nvidia; ma nello scenario della generazione sequenziale dei token output, basta che abbassi radicalmente i tempi di attesa per spingere il cliente a pagare per "attendere qualche secondo in meno”. Agent per coding, assistenti customer service, analisi finanziaria, ricerche legali, supporto ricerca farmaceutica, digital humans in tempo reale: il valore di questi carichi non dipende solo dal prezzo per milione di token, ma se la catena uomo-agent resta bloccata o meno.
II. Gli ordini sono reali, ma non senza un costo
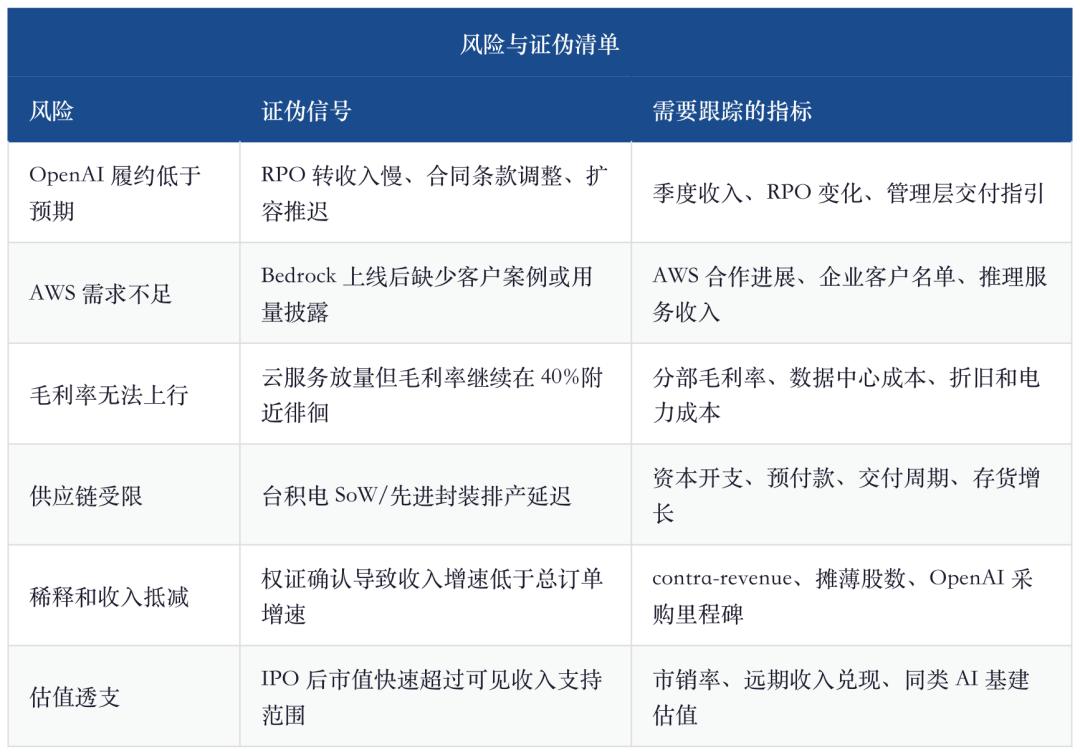
La forza principale di Cerebras ora è la visibilità degli ordini. Il contratto OpenAI, la collaborazione con AWS e la clientela dal Medio Oriente hanno spinto la società da “startup hardware avanzata ma di nicchia” a “IPO di infrastruttura AI”. Ma occorre distinguere i ruoli: OpenAI rappresenta la visibilità delle entrate, AWS verifica il canale, i clienti mediorientali sono la fonte storica; non vanno confusi come la stessa certezza.
Informazioni correlate a OpenAI mostrano che l’accordo di capacità di calcolo da 750MW di Cerebras vale oltre 20 miliardi di dollari, espandibile a 2GW entro il 2030. Stimando la consegna su tre anni, il contratto iniziale implica circa 6,7 miliardi di dollari di potenziale entrate annue. Intanto, OpenAI riceve warrant legati alle milestones d’acquisto, con la possibilità di acquistare 33,5 milioni di azioni Cerebras; questo porta due effetti: uno è la diluizione, l’altro è che il valore dei warrant può essere usato per compensare i ricavi, abbassando il riconoscimento del netto futuro.
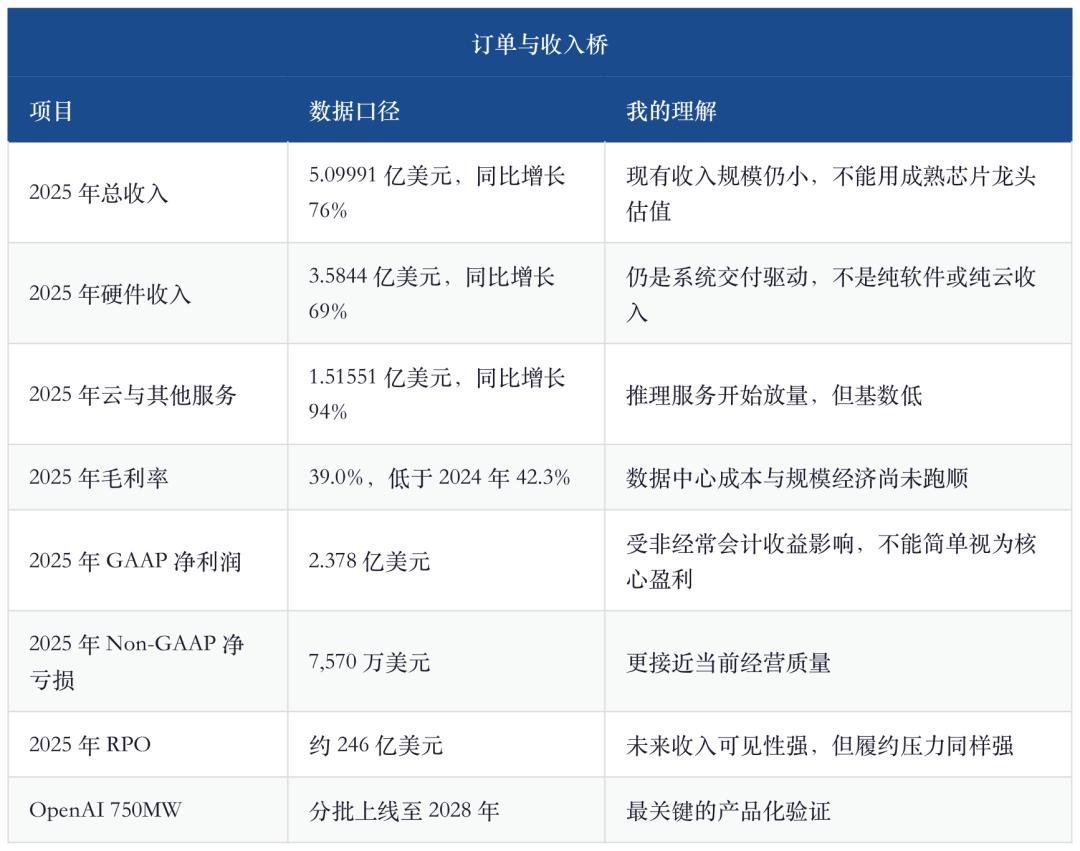
"Le entrate sono salite a 510,0 milioni nel 2025."
Questo dato SEC sulle entrate va letto insieme ad un altro fatto: nel 2025 MBZUAI ha contribuito per il 62% delle entrate, G42 per il 24%; nel 2024 G42 è arrivato all’85%. Ovvero, Cerebras non ha sviluppato una curva SaaS proveniente da una clientela enterprise dispersa, ma sono pochi clienti enormi che tirano la curva verso l’alto. In futuro OpenAI potrebbe sostituire i clienti mediorientali come fonte principale, la qualità del cliente migliora ma il rischio di concentrazione resta.
Gli ordini nelle infrastrutture AI hanno modificato il loro nucleo: i clienti su larga scala iniziano a bloccare capacità di calcolo, energia, chip e risorse cloud con contratti pluriennali. Cerebras è l'emblema di questa era. Gli ordini sono così grandi da permettere ad una società con 510 milioni di dollari di entrate nel 2025 di valere decine di miliardi; ma più grande l’ordine, più rischi su capex, consegna, finanziamento, rendimento, data center energizzato diventano centrali nel business.
III. La collaborazione con AWS verifica il modello di business più di OpenAI
OpenAI dimostra che “i laboratori di modelli di punta necessitano questa velocità”, AWS dimostra che “questa velocità può essere venduta alle aziende”. Sono due domande diverse. OpenAI può pagare un premium strategico per il proprio prodotto; gli enterprise che usano Cerebras via Bedrock valutano con freddezza prezzo, latenza, throughput, stabilità, localizzazione dati e fattura cloud.
Il punto chiave dei comunicati AWS non sono aggettivi come "inferenza più veloce", ma il fatto che l’inferenza venga segmentata in prefill e decode: Trainium si occupa del prompt processing, CS-3 della generazione output. Se questa architettura funziona significa che le cloud vendor non vedono più i chip AI solo come acceleratori, ma spezzano la pipeline di inferenza. Il ruolo di Cerebras qui è come motore di decode di fascia alta, non una completa sostituzione del chip AWS proprietario.
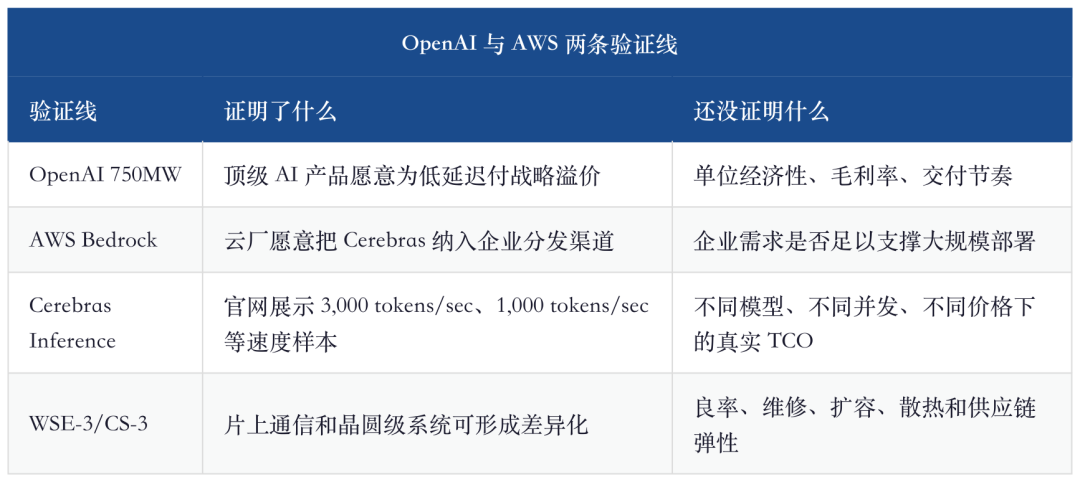
Do più peso ad AWS perché può trasformare Cerebras da “fornitore dedicato OpenAI” a “capabilità acquistabile nel cloud”. Se i clienti enterprise su Bedrock pagano davvero per la bassa latenza, la struttura dei ricavi Cerebras passa da grandi contratti a modello scalabile di utilizzo; viceversa, se Bedrock non genera grande domanda, il contratto OpenAI appare più come acquisto strategico che come segnale di prezzo di mercato aperto.
IV. Valutazione: 125 dollari e 160 dollari sono due storie diverse
Il valore IPO non va visto solo dalle entrate 2025, sarebbe assurdo; né va guardato solo all’entrata potenziale 2029, ignorando i rischi di consegna. L’approccio giusto è a tre livelli: base 2025, RPO firmati, opzioni di espansione OpenAI/AWS.
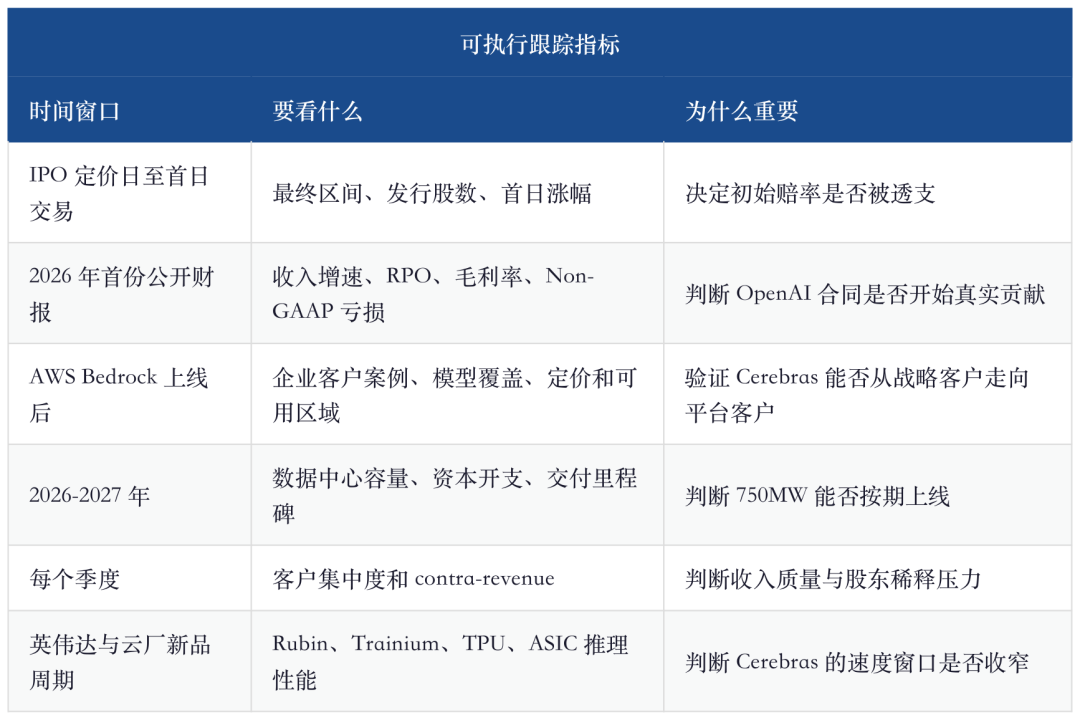
Dopo il round H di febbraio 2026, Cerebras vale circa 23 miliardi di dollari. Il documento ufficiale di avvio roadshow IPO indica i range originali di 28 milioni di azioni, prezzo 115-125; Reuters riporta che la società pensa di alzare a 150-160, con 30 milioni di azioni. Da sottolineare: alla data di stesura, il range ufficiale resta 115-125, l’aumento è notizia di mercato non ufficialmente confermata.

Il mio schema di pricing è:Se Cerebras è solo un’azienda hardware con 510 milioni di dollari di entrate 2025, margine lordo del 39%, ancora in perdita, una valutazione sopra i 30 miliardi è cara; se riesce a generare più di 6 miliardi di entrate nette annualizzate OpenAI e AWS dimostra la domanda enterprise, i 30 miliardi non sarebbero cari. Quindi non è questione di valutazione statica, ma di percorso di realizzazione.
L’errore psicologico più pericoloso è trattare l’RPO come ricavi, i ricavi come profitti, i profitti come cash flow libero. Cerebras deve prima ordinare a TSMC, costruire o affittare data center, comprare energia e sistemi di cooling, poi consegnare la capacità ai clienti. Più grande il contratto, più enorme il fabbisogno di capitale; se contratti clienti, warrant, loan e costo data center si accumulano, il bilancio breve termine sarà brutto.

V. Il suo significato per la filiera: TSMC, AWS e Nvidia non sono perdenti
Se Cerebras avrà successo, il significato diretto per l’industria non è “crollo Nvidia”, ma che l’infrastruttura AI si trasforma in una combinazione multipla. Training e inferenza generica restano dominati dalle GPU, i chip proprietari cloud gestiscono i carichi interni, Cerebras e sistemi wafer-level coprono parte degli scenari inferenziali premium a bassa latenza. In altre parole, è una fetta di mercato aggiuntiva, non una sostituzione zero-sum.
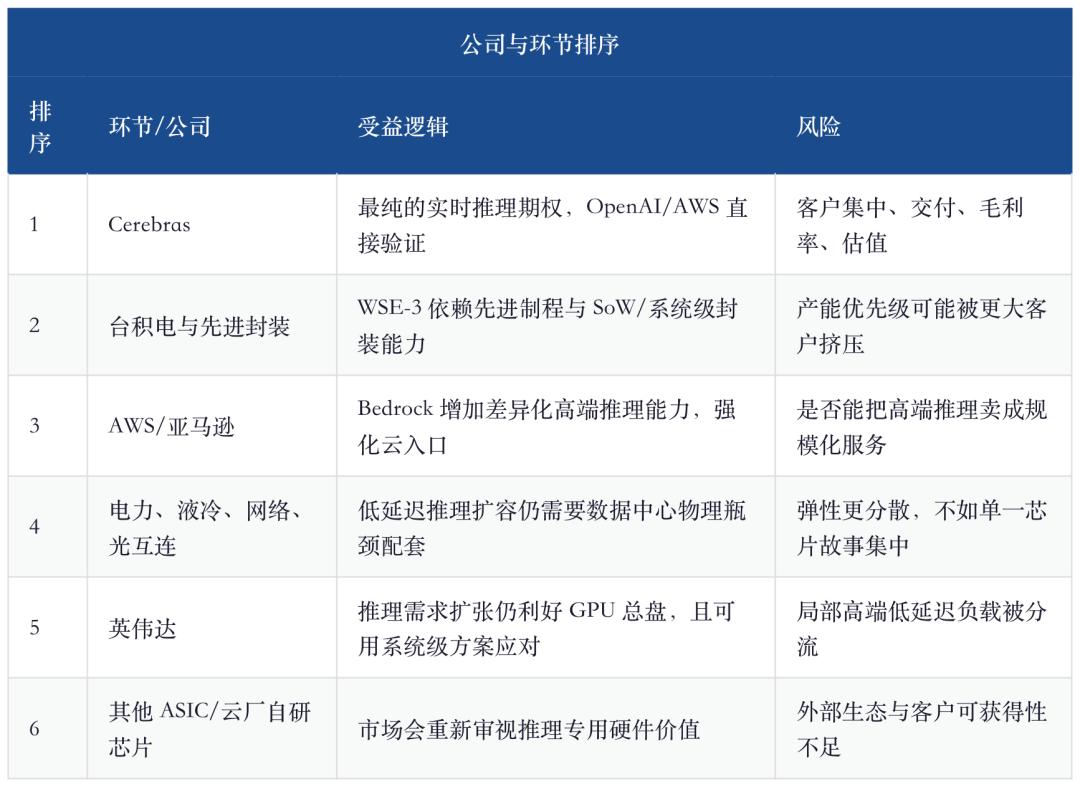
La pipeline Anthropic mostra che le aziende AI stanno passando dalla “sperimentazione del modello” alla “implementazione workflow”. Anche il valore di Cerebras va visto qui: se la frequenza d’uso, profondità della catena e richieste di risposta degli agent enterprise continueranno a crescere, l’inferenza a bassa latenza diventa il nuovo servizio premium cloud. Viceversa, se gli agent restano a demo, pilota e poco più, la capacità inferenziale premium di Cerebras rischia di essere offerta anticipata, domanda posticipata.
VI. Opinione contraria: perché potrebbe essere un titolo difficile da detenere
Riconosco la strategia tecnica di Cerebras, ma non credo sia un titolo facile da detenere. Le ragioni sono quattro.
Primo, la concentrazione clientelare renderà ogni trimestre stressante. Nel 2025 MBZUAI e G42 sommano l’86% delle entrate, in futuro OpenAI sarà un ulteriore variabile unica. La qualità dei clienti è alta, ma occorre accettare la realtà: il modello di ricavi non deriva da migliaia di clienti enterprise dispersivi.
Secondo, il margine lordo non è ancora provato. Nel 2025 è del 39%, inferiore al 42,3% del 2024. Se la scalabilità del cloud inferenziale non fa salire il margine, il modello di business assomiglierà a un operatore data center capitale-intensivo, non a una società di chip ad alto margine. Il mercato può dare multipli alti alla tecnologia rara, ma non software multipli ad aziende che fanno business a basso margine e capitale pesante.
Terzo, la supply chain e complessità ingegneristica sono enormi. Il vantaggio dei chip wafer-level viene dal “grande”, il rischio pure. Yield, packaging, alimentazione, liquid cooling, manutenzione, ridondanza di sistema, pianificazione TSMC, energizzazione data center: ognuno di questi può rallentare la realizzazione dell’RPO rispetto alle aspettative degli investitori.
Quarto, la competizione non si ferma. Nvidia non abbandona l’inferenza, le cloud vendor continuano lo sviluppo di ASIC proprietari, Google TPU, AWS Trainium, Broadcom/Marvell ASIC, Groq ecc. continueranno a far evolvere l’economia inferenziale. La finestra di Cerebras viene dal “essere ora abbastanza veloce”, ma il fossato a lungo termine dipende da software, integrazione clienti, distribuzione cloud e capacità di consegna.
VII. Conclusione personale: osserva, aspetta, non considerare la scarsità un margine di sicurezza
Cerebras è l’IPO hardware AI del 2026 da analizzare con attenzione. Non è solo narrativa: specifiche sul sito, 750MW OpenAI, inferenza disaccoppiata AWS, crescita ricavi 76% nel 2025, 24,6 miliardi di RPO, tutto indica che è sulla filiera reale. Ma non è nemmeno un asset a basso rischio: nel 2025 core business in perdita, margine non alto, concentrazione clienti estrema, consegna dipendente da TSMC e data center, valutazione potenzialmente gonfiata dal fervore IPO.
L’approccio operativo che adotterei è su tre livelli:
- Se il prezzo finale è vicino a 115-125 dollari e il primo giorno non cresce eccessivamente, si può considerare un’opzione infrastutturale inferenziale AI da osservare con posizione ridotta.
- Se il prezzo si spinge su 150-160 dollari e il primo giorno continua a salire molto, il payout è già compresso, meglio aspettare il primo trimestre di earnings per verificare RPO, margine lordo e avanzamento AWS.
- Se dopo l’IPO ci saranno ampie oscillazioni per lock up, preoccupazioni di delivery, o correzione market AI infrastrutturale, potrebbero emergere opportunità di acquisto migliori.
Il corretto schema d’investimento non è “sostituisce Nvidia”, ma “l’inferenza realtime diventa nuova layer di infrastruttura”. Finché il prodotto AI evolve da Q&A lento a collaborazione realtime, Cerebras avrà posto; ma per trasformare quel posto in rendimento azionario, deve dimostrare consegna puntuale, profitto e clientela fuori da OpenAI.
In conclusione:Cerebras merita un monitoraggio e una scommessa al prezzo giusto, ma non è "un nuovo re dei chip AI per vincere stando fermi". È più una scommessa ad alto payout: se l’inferenza realtime diventa la prossima linea AI, sarà cruciale; se il mercato insegue solo la narrativa non-Nvidia, sarà molto volatile.
Esclusione di responsabilità: il contenuto di questo articolo riflette esclusivamente l’opinione dell’autore e non rappresenta in alcun modo la piattaforma. Questo articolo non deve essere utilizzato come riferimento per prendere decisioni di investimento.
Ti potrebbe interessare anche
In tendenza
AltroESIM (Depinsim) fluttua dell'81,7% nelle ultime 24 ore: volume degli scambi in aumento del 143% scatena forti oscillazioni per bassa liquidità
AstraNova (RVV) ampiezza del 24 ore del 44,8%: l’iniezione di liquidità dai depositi CEX del team ha causato un’impennata del volume degli scambi seguita da una correzione del prezzo