
Ang estratehiya ni Jensen Huang: Bawat daan ng AI computing power, nandoon ang Nvidia na naghihintay

Dalawang bagay ang ginawa ngayon ni Jensen Huang sa Taipei, China: inilagay ang CUDA sa laptop, at dinala ang inference ng trilyong parameter sa tabi ng mesa.

Hindi ito ang NVIDIA na nakikipag-agawan ng negosyo sa mga cloud provider. Ang AWS, Azure, at Google Cloud ang ilan sa pinakamalalaking kliyente ng NVIDIA na taun-taong bumibili ng GPU mula sa kanila ng bilyong dolyar. Hindi sasalungatin ng NVIDIA ang sarili nitong ginto.
Ang totoong nangyayari ay: pinalalawak ng NVIDIA ang pagkakakitaan nito. Dati iisa lang ang ruta sa AI compute—bumili ng GPU ng NVIDIA at ilagay sa data center ng cloud provider. Ngayon, may dalawa pa: RTX Spark laptop at DGX Station desktop. Kahit anong ruta piliin mo, nandoon ang NVIDIA sa umpisa. Tinatawag ni Jensen ang sarili niyang "infrastructure company," ibig sabihin: hindi mahalaga kung saan tatakbo ang AI, ang mahalaga ay may daan na inilatag ang NVIDIA.
Unang beses nakapasok ang CUDA sa backpack
Ang tunay na fortress ng NVIDIA sa loob ng tatlumpung taon ay hindi ang GPU, kundi ang CUDA. May 7.5 milyong developer na tumatrabaho dito; PyTorch, TensorRT, TensorRT-LLM, llama.cpp—ang pinaka-optimal na path para sa mga mainstream na AI framework ay narito lahat. Dalawampung taon ang itinaguyod, at walang kumpanyang nakapag-duplicate pa nito.
Ang problema lang, palagi lang nakakulong ang CUDA sa data center. Hindi natutuloy sa magagaan na laptop ang code na sinulat sa cloud, hindi suportado ng Qualcomm Snapdragon X, at ang Apple M series ay nasa ibang mundo.
Binuwag ng RTX Spark ang pader na ito. ARM CPU na may 20 cores at 6144 CUDA cores na Blackwell GPU, 128GB unified memory, 1 PetaFLOP na AI compute—lahat ito sa 14mm na kapal ng laptop. Nakipagkasundo na ang NVIDIA sa 100 Windows software vendors; native support na para sa TensorRT, PyTorch CUDA backend, at TensorRT-LLM. Ang mga engineer na nagsulat ng CUDA sa data center sa loob ng 3 taon, maaaring gumamit ng RTX Spark laptop na halos hindi na magbabago ng code.

Hindi talo ang Qualcomm sa compute power, kundi natalo ito sa narrative. Tatlong taon ginastos ng Snapdragon X para mapaganda ang reputasyon ng Windows on ARM, nagawa nilang halos mapantayan ang efficiency ng Apple—pero isang bagay lang ang ‘di pa rin makuha: ang mga AI developer. Ang grupong iyon ay nasa labas pa rin ng laro, naghihintay ng Windows laptop na kayang magpatakbo ng CUDA.
Dumating ang NVIDIA dala ang CUDA, kaya nandoon na sila at naghintay.
May mga baraha rin naman ang Snapdragon X. Sa US, may 10% sila ng Windows laptop market na higit $800, may higit 80 OEM design, nag-release ang X2 Elite nitong unang kalahati ng taon, may NPU na diretso sa 80 TOPS, at may tunay na advantage sa paguna. Pero kung walang CUDA, ang Qualcomm ay laging alternatibo lang para sa AI developers.
Pangalawang portahan ng bayad sa tabi ng mesa
Ibang-iba naman ang lohika ng isa pang produkto, at magkaiba rin ang target na kliyente.
DGX Station for Windows na base sa GB300 Grace Blackwell Ultra chip, lokal na tumatakbo sa hanggang 1 trilyong parameter na modelo, kayang suportahan ang daan-daang AI agent nang sabay, may presyo na $80,000 hanggang $125,000, ilalabas Q4, at magla-launch sa ASUS, Dell, Gigabyte, HP, MSI, at Supermicro.

Ang bibili ng makinang ito ay hindi indibidwal, kundi mga kumpanyang kailangan ng matatag na AI inference, sensitibong data, at ayaw ng buwan-buwan na malaking bill sa cloud. Mga risk model ng financial institutions, kontrata sa law firm, at image analysis ng ospital—mga workload na araw-araw kailangan, at kung sa cloud B300 instance by the hour ka magbabayad, mababawi mo ang $100,000 sa desktop sa 4-6 na buwan, saka na lang ang puro ipon.
Pansinin ang piniling OEM partners ng NVIDIA: ASUS, Dell, HP, Supermicro—lahat enterprise channel, hindi consumer brands. Nakasulat na sa specs ang target na kliyente.
May isa pang implicit na bentahe ang DGX Station: data compliance. Ang cloud inference ay nangangahulugang lalabas ng lokal network ang data; pahirap na pahirap ang cross-border na daloy ng customer data sa ilalim ng financial regulation, at humihigpit pati na privacy policy ng medical data. Sa ganitong kumpanyang, “data doesn’t leave the premises” ay hindi extra kundi requirement. Hindi dahil mura binibili ang DGX Station kundi dahil iyon lang ang opsyon.
Ito ang pangalawang port ng koleksyon ng bayad sa enterprise compute market ng NVIDIA—una ay ang GPU sa data center ng cloud provider, pangalawa ay ang GPU ng enterprise mismo sa tabi. Parehong galing NVIDIA, parehong kita para sa kanila.
Kalagayan ng cloud provider: hindi “inaagawan,” kundi “nadagdagan ng opsyon”
Ang NVIDIA ang pinakamalaking hardware supplier ng cloud provider, hindi sila magkalaban. Benta ng isang DGX Station, may kita; expansion ng cloud data center, mas malaking kita sa GPU. Puwedeng mangyari pareho sabay, at malamang mangyari nga—AI inference market ay lumalagong mahigit 40% taun-taon, sapat ang laki ng ‘pie’ para sa lokal at cloud expansion.
Ang tunay na apektado ay ang mga eksena na dati “kailangang mag-cloud,” pero nagkaroon ng local na opsyon. Para sa cloud provider, hindi ito bawas sa gross revenue kundi sa bargaining power—kapag ang procurement manager ay may quote ng DGX Station sa negotiation, hindi na puwedeng basta magtaas-presyo ang cloud provider.
Sa nakaraang dalawang taon, tumataya rin ang AWS at Google sa sarili nilang inference chips—AWS Trainium, Google TPU—bahagi ng dahilan ay para mabawasan ang dependence nila sa NVIDIA. Pinakakomplikado pa ang sitwasyon dahil sa DGX Station: bibili pa rin sila ng GPU mula sa NVIDIA, pero ngayon kakompetensiya na rin ng desktop hardware ng NVIDIA mismo sa inference layer. Hindi ito magbubunga ng krisis sa iilang quarters, pero habang lumalaki ang on-premise inference, mula supplier relationship, magiging mas komplikado pang kooperasyon-kompetisyon ang dynamics ng NVIDIA at cloud provider.
Pinakamaipit ang Microsoft sa gitna. Sila ang pangunahing katuwang sa RTX Spark, ka-partner sa pagtransform sa Windows bilang AI agent OS, at ang Surface Laptop Ultra ang unang RTX Spark laptop—pareho ang direksyon nilang dalawa. Pero ang Azure ng Microsoft ay pinakamalaking AI cloud service; ngayon, kaki-kumpitensya na rin nila ang desktop machine ng sariling partner. Hindi ito magbubunga agad ng sagupaan, pero karapat-dapat panoorin kung paano ito haharapin.
Mas malalim pa ang moat ng Apple kaysa sa RTX Spark
Sa pag-release ng RTX Spark, direkta nang tinukoy ang Apple, at halos lahat ng media ay nagsabing panglaban ito sa M5.
Hindi ito lubos na tama. Hindi nasa chip performance ang moat ng Apple. M5 Max ay may 153GB/s memory bandwidth, at may edge kapag modelong mas malaki sa 24GB parameter. Pero ang mas malalim na pader ay nasa software—walang Windows version ang Final Cut Pro, wala ring Windows version ang Logic Pro, at mahigit isang dekada nang built-up ang creative workflow sa macOS; hindi basta GPU ang makadidisplace dito.
Inanunsyo ng Adobe ang migration ng Photoshop at Premiere Pro para mag-support ng RTX Spark—pinakamalakas na baraha ng NVIDIA sa creative side—pero mula software migration hanggang totoong paglipat ng user, mahaba pa ang transition ng habit.
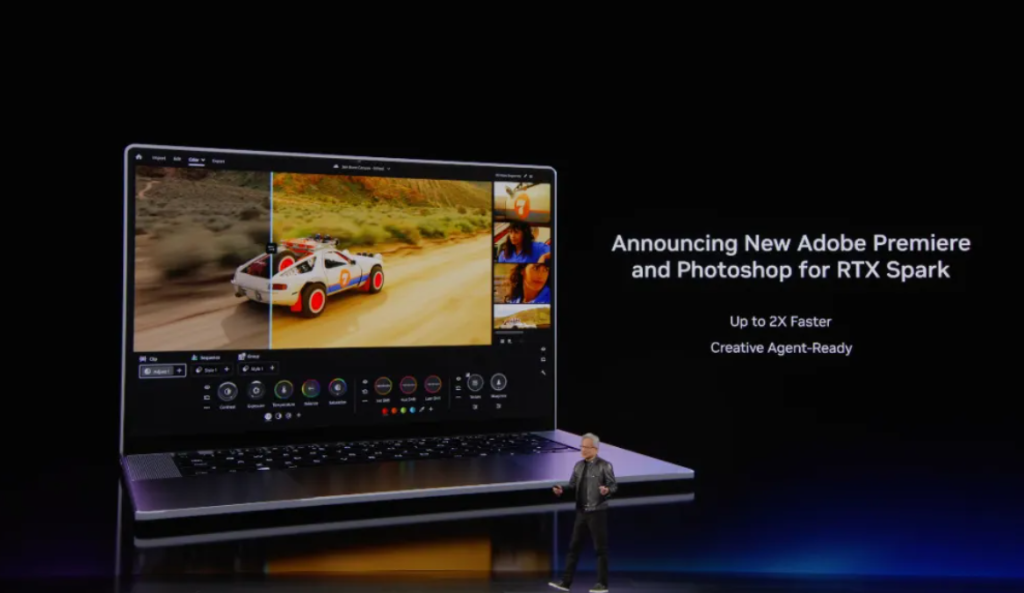
Ang kayang talagang mapabago ng NVIDIA mula sa Apple ay mga AI/ML developer—na dati nang gumagamit ng CUDA sa Windows at Linux. Binibigyan lang sila ng RTX Spark ng mas portable na makina, at hindi kalaban ng Apple sa creative. Ang bersyong kailangang paghandaan ng Apple ay hindi ngayong taglagas kundi sa 2028 kapag matured na ang Rubin Spark.
Ang tanong na tinatago ng NVIDIA
May isang linyang tahimik lang ang NVIDIA sa specs: ang integrated GPU ng RTX Spark ay katapat ng RTX 5070.
Kumikita ng NVIDIA sa discrete GPU sa loob ng tatlumpung taon; Gaming FY2026 ay $16B revenue, 41% growth year-on-year. Kung totoo ngang ang RTX Spark ay katapat ng RTX 5070 sa performance, baka hindi na kailangan ng high-end laptop buyer ng discrete graphic card—ang “GPU” ay nilagom na sa SoC, at pareho lang din, kita pa rin ng NVIDIA, iba lang ang anyo.
Short term, may upper hand pa rin ang discrete GPU sa power consumption at absolute performance. Pero noong lumabas ang Apple M1 noong 2020, sabi ng lahat hindi mamamatay ang discrete GPU; makalipas ang tatlong taon, ang mga MacBook na may Intel discrete GPU ay nawala na sa market. Sinusugal ng NVIDIA ang rutang ito, umaasang sapat ang laki ng incremental market mula sa AI PC para punan ang pagliit ng discrete GPU. Hindi naman mali, pero mas mataas ang risk kaysa sa ipinapakita sa launch stage.
Ano ang dapat tutukan
Ang taglagas ay ang tunay na validation window. Labas na ang presyo ng unang batch ng RTX Spark laptop, at kapag tumakbo na sa real device ang CUDA ng devs, doon pa lang lilipat ang kwento mula Computex stage patungong financial reports.
Pinakamahalaga ang dalawang numero: OEM pricing at compatibility test ng Windows ARM. Inaasahan na magsisimula sa $1400 ang presyo, bababa ang demand kung aabot sa higit $1800. Kung compatibility ay tulad noong pumasok ang Qualcomm, aabot ng 12-18 buwan bago maging mature; hindi naman hihinto ang market accumulation ng Qualcomm habang iyon ay nagaganap.
Midterm, tingnan ang benchmark ng Qualcomm X2 Elite at ang unang enterprise customers ng DGX Station—ang una ay nagsasabi kung gaano kalakas ang laban ng Qualcomm, ang huli ay magsasabi ng tunay na laki ng demand para sa enterprise-local inference. Kung magsimulang magbaba ng inference pricing ang cloud provider dahil sa DGX Station, ibig sabihin ay kinikilala na mismo nila ang competitive pressure, at maaaring mapabilis ang pagbago ng presyo.
Sa assets, ang NVDA ay pangunahing linya, mula isang toll booth ay naging tatlo, lumalaki ang TAM, at ang OEM pricing sa taglagas ang magiging dividing line sa malapit na panahon. Ang QCOM ang pinakaapektado, masama para sa narrative sa AI developer, pero matibay pa rin sa consumer, at may rebound window pa ang X2 Elite. Hindi problema ang cloud provider sa short term; midterm, nababawasan lang ang bargaining power, hindi ang revenue. Iba ang dalawang bagay na iyon. Ang MSFT ay double-sided ang taya, at nakasalalay ang effect sa scale ng inference. ARM at MediaTek ay tiyak na maliit na benepisyaryo dito.
Disclaimer: Ang nilalaman ng artikulong ito ay sumasalamin lamang sa opinyon ng author at hindi kumakatawan sa platform sa anumang kapasidad. Ang artikulong ito ay hindi nilayon na magsilbi bilang isang sanggunian para sa paggawa ng mga desisyon sa investment.
Baka magustuhan mo rin
Trending na balita
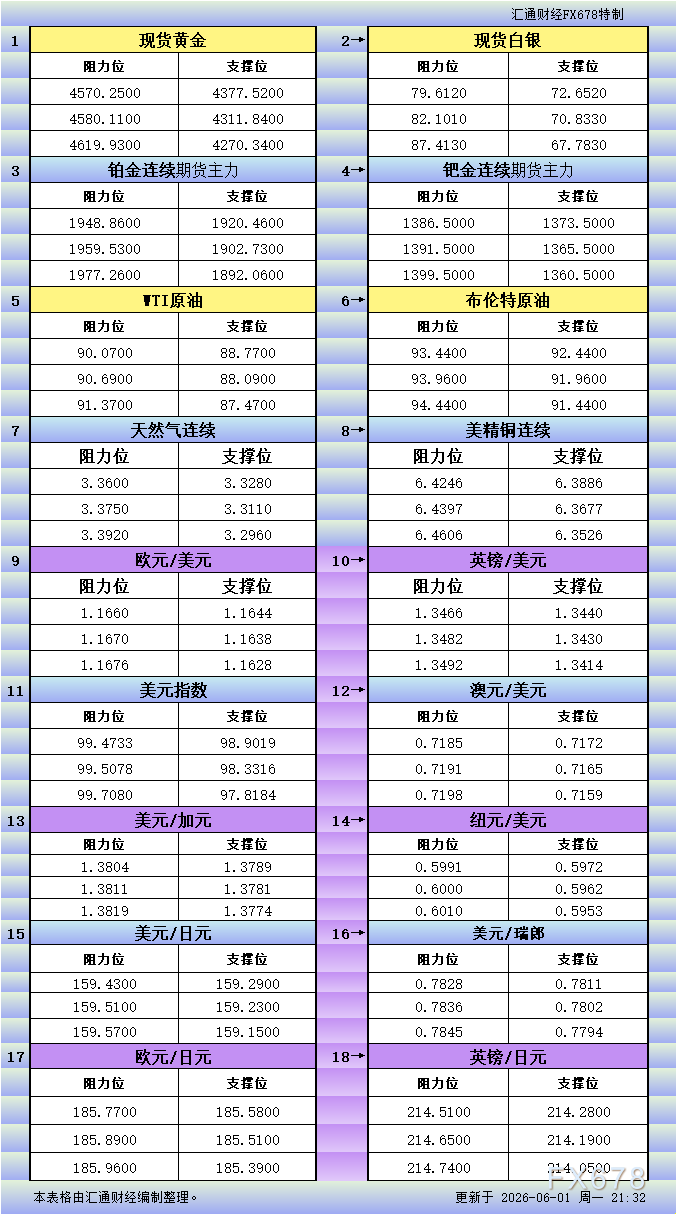
Higit paHunyo 1 Pag-update sa Support at Resistance ng US Market: 18 Uri ng Support at Resistance (Ginto, Pilak, Platinum, Palladium, Langis, Likas na Gas, Tanso at Sampung Pangunahing Currency Pair)
Ang spot gold ay nagkaroon ng pinakamalaking pag-urong ngayong taon na higit sa 26%, maraming bangko ang nakakabit ang istraktural na deposito na may nabawasang kita.