Um chip vale mais do que um prato de comida: o maior IPO da história de chips de IA aconteceu! Cinco veteranos da indústria de chips apostam há dez anos na explosão do poder de computação em IA


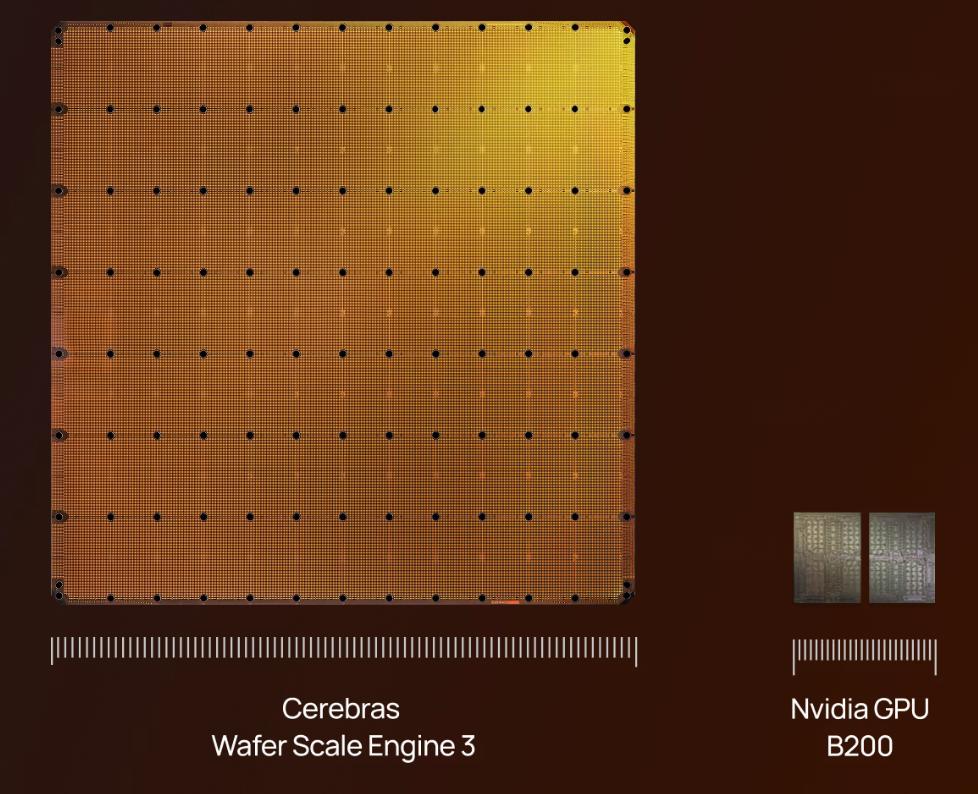
Normalmente, os chips de computador que vemos têm o tamanho de uma unha, e as GPUs caberiam na palma da mão. Mas, uma empresa da Califórnia chamada Cerebras fabricou um chip do tamanho de um prato grande, com mais de 200 milímetros de diâmetro, área de 46.225 mm² e integrando 4 trilhões de transistores.
A empresa foi listada na Nasdaq em 14 de maio de 2026, com preço inicial de US$ 185 e abriu a US$ 350. No primeiro dia, teve alta de 89% e o valor de mercado chegou a US$ 75 bilhões. Dos cinco cofundadores, quatro vieram de uma empresa de servidores adquirida pela AMD, a SeaMicro, e o outro é do MIT. Eles trabalham silenciosamente nesse projeto desde 2015 e, agora, com o chip em escala de wafer, estão na linha de frente da corrida por poder computacional em IA.

(Fonte: cerebras.ai)
O principal produto da Cerebras é chamado de Wafer-Scale Engine (WSE), que atualmente está em sua terceira geração, a WSE-3. A fabricação tradicional de chips envolve cortar um wafer em centenas de pequenos chips, enquanto a Cerebras faz o oposto: não corta, transforma um wafer inteiro em um único chip.Cerebras vai na contramão do convencional, mantendo o wafer inteiro sem cortes, criando um chip único a partir dele.Nesse wafer inteiro, são integrados 84 tiles virtuais, cada um com cerca de 10. 700 núcleos, totalizando 900 mil núcleos de processamento em todo o chip.
Esses núcleos se conectam por meio de uma rede 2D mesh on-chip, cada um contando com um roteador de cinco portas, suportando transmissão de dados em quatro direções e operações de leitura/gravação local. A largura de banda da memória do chip atinge 21 petabytes por segundo, e a largura de banda da rede chega a 214 petabytes por segundo.

(Fonte: cerebras.ai)
O chip WSE-3 é produzido pela TSMC com tecnologia de 5 nanômetros. A área de cada núcleo de processamento é de cerca de 38 mil micrômetros quadrados, metade ocupada por SRAM local de 48 KB e metade por circuitos lógicos. O chip todo alcança 44GB de SRAM. Toda a memória está distribuída ao lado dos núcleos, de modo que a distância física para acesso é de poucas dezenas de micrômetros, dispensando a necessidade das GPUs convencionais por HBM externo. Segundo a Cerebras, na mesma área de silício, a largura de banda da memória deles é cerca de 200 vezes maior que a de uma GPU.

(Fonte: cerebras.ai)
Essa arquitetura é especialmente adequada para processar esparsidade não estruturada em redes neurais. A GPU tradicional calcula tudo, independentemente do peso ser zero ou não. Na Cerebras, o valor zero já é filtrado na origem, e só os dados não zero trafegam entre os núcleos pela rede do chip.Cada pacote de dados contém 16 bits de informação e 16 bits de controle. Ao receber, o núcleo executa automaticamente a operação de multiplicação acumulada, o que evita muitos cálculos desnecessários, acelerando modelos altamente esparsos.
Segundo o whitepaper tecnológico da empresa, para operações BLAS de nível abaixo das multiplicações gerais de matrizes, como multiplicação matriz-vetor ou vetor-escalar, chips tradicionais ficam limitados pela largura da banda da memória e não atingem uso total. Com a largura de banda da Cerebras sendo altíssima, a utilização permanece elevada.
(Fonte: cerebras.ai)
Outra tecnologia chave da Cerebras é o Weight Streaming. Ao treinar grandes modelos, os pesos do modelo não ficam armazenados no chip, mas num dispositivo externo chamado MemoryX, sendo transmitidos conforme necessário para o WSE-3. Para cada camada da rede, os pesos são buscados da DRAM externa e do flash e encaminhados pelo I/O do chip até os núcleos de processamento.
Quando cada peso chega ao núcleo, realiza multiplicações acumuladas em lote com os valores locais de ativação. Terminada a operação, os pesos são descartados, sem permanecer no chip. Esse método dispensa a limitação do tamanho do modelo pelo limite de memória do chip, viabilizando suporte para modelos de trilhões de parâmetros.

(Fonte: cerebras.ai)
Em software, a Cerebras oferece uma cadeia completa de ferramentas de compilação. Isso permite mapear automaticamente modelos criados em PyTorch ou TensorFlow sobre os 900 mil núcleos do chip. Para modelos tipo Transformer, tensores de ativação têm três dimensões: tamanho do batch, comprimento de sequência e dimensão de embedding. O compilador fatia a dimensão de embedding ao longo do eixo X do chip, e o batch mais sequência no eixo Y.
Ao calcular multiplicações de matrizes, os pesos são transmitidos junto às linhas para todos os núcleos da mesma coluna, acionando as operações de multiply-add, seguidas de redução parcial na direção da coluna. O resultado fica distribuído sobre o chip, pronto para o próximo cálculo. Todo o agendamento de operações é feito de forma estática, carregando instruções antes da execução, sem alterá-las durante o processo.

(Fonte: cerebras.ai)
Os cinco cofundadores da Cerebras têm grande experiência em chips e sistemas.
O CEO Andrew Feldman se formou em Stanford e fundou a SeaMicro, comprada pela AMD por US$ 357 milhões.
O CTO Sean Lie é bacharel e mestre em Engenharia Elétrica e Ciência da Computação pelo MIT. Na SeaMicro, foi arquiteto de virtualização IO, tornando-se fellow da AMD após a aquisição.
O arquiteto de sistemas Jean-Philippe Fricker é mestre pela EPFL (École Polytechnique Fédérale de Lausanne) e trabalhou como arquiteto de hardware na DSSD, SeaMicro, Alcatel-Lucent e Riverstone Networks.
O arquiteto de tecnologia avançada, Michael James, tem diplomas em neurobiologia molecular, matemática e ciência da computação pela UC Berkeley e foi responsável por sistemas distribuídos na SeaMicro.
O ex-CTO (agora aposentado) Gary Lauterbach possui mais de 50 patentes. Ele foi engenheiro de destaque da Sun Microsystems, liderando o design dos microprocessadores UltraSPARC III e UltraSPARC IV.
O modelo de negócios da Cerebras depende principalmente da venda do sistema completo CS-3, um sistema turnkey ao redor do chip WSE-3, adequado para racks padrão de datacenters. Os principais clientes são institutos de pesquisa e empresas, incluindo a companhia de inteligência artificial G42 dos Emirados Árabes Unidos e a Universidade Mohamed bin Zayed de Inteligência Artificial. Segundo documentos da IPO, em 2025, a Cerebras faturou US$ 510 milhões, sendo 24% oriundos da G42 e 62% da MBZUAI. O lucro líquido do ano foi de US$ 238 milhões, revertendo o prejuízo de US$ 482 milhões do ano anterior.
A Cerebras tentou abrir capital em 2024, mas, na época, dependia fortemente do cliente G42, responsável por 87% da receita. Como qualquer operação relacionada aos Emirados Árabes passa pelo Comitê de Investimento Estrangeiro dos EUA, mesmo após aprovação, a empresa retirou o pedido de IPO. Na nova abertura de capital, a concentração melhorou: o maior cliente, MBZUAI, agora responde por 62% da receita, mas juntos, os dois principais clientes ainda somam 86%, mantendo risco de concentração.
A abordagem tecnológica da Cerebras é única no segmento de chips para IA. A maioria dos concorrentes copia a arquitetura GPU convencional: muitos pequenos núcleos com HBM. A Cerebras aposta em um wafer gigante para resolver o problema, o que traz vantagens claras em cálculo esparso e inferência de modelos grandes. Porém, enfrenta desafios de custo e rendimento na fabricação.
Se houver um defeito fatal em qualquer parte do wafer, todo o chip pode ser comprometido. A Cerebras enfrenta isso com links redundantes e mecanismos automáticos de correção de erro no projeto. O consumo de energia e dissipação de calor do chip em escala de wafer são desafios de engenharia, e o sistema CS-3 adota uma solução especial de refrigeração líquida.
Com empresas como OpenAI, Anthropic e SpaceX próximo de abrir capital, chips para IA viraram o foco do mercado financeiro. A Cerebras, como o primeiro puro player de chips de IA a estrear na Nasdaq, viu suas ações subirem 89% no primeiro dia, sinalizando positivamente para os próximos a chegar ao mercado.
Mas a competição no setor de chips de IA está esquentando. Além da Nvidia, AMD, Intel e várias startups estão lançando novos produtos. Se a proposta em escala de wafer da Cerebras vai se consolidar no mercado mainstream de treinamento de IA, depende de atrair mais clientes e do teste do tempo.
Aviso Legal: o conteúdo deste artigo reflete exclusivamente a opinião do autor e não representa a plataforma. Este artigo não deve servir como referência para a tomada de decisões de investimento.
Talvez também goste
TAC (TAC) oscila 46,4% em 24 horas: volume de negociação dispara e provoca reação especulativa