
Un chip vale quanto un piatto: la più grande IPO di chip AI della storia! Cinque veterani dei chip scommettono sul boom della potenza di calcolo AI in dieci anni


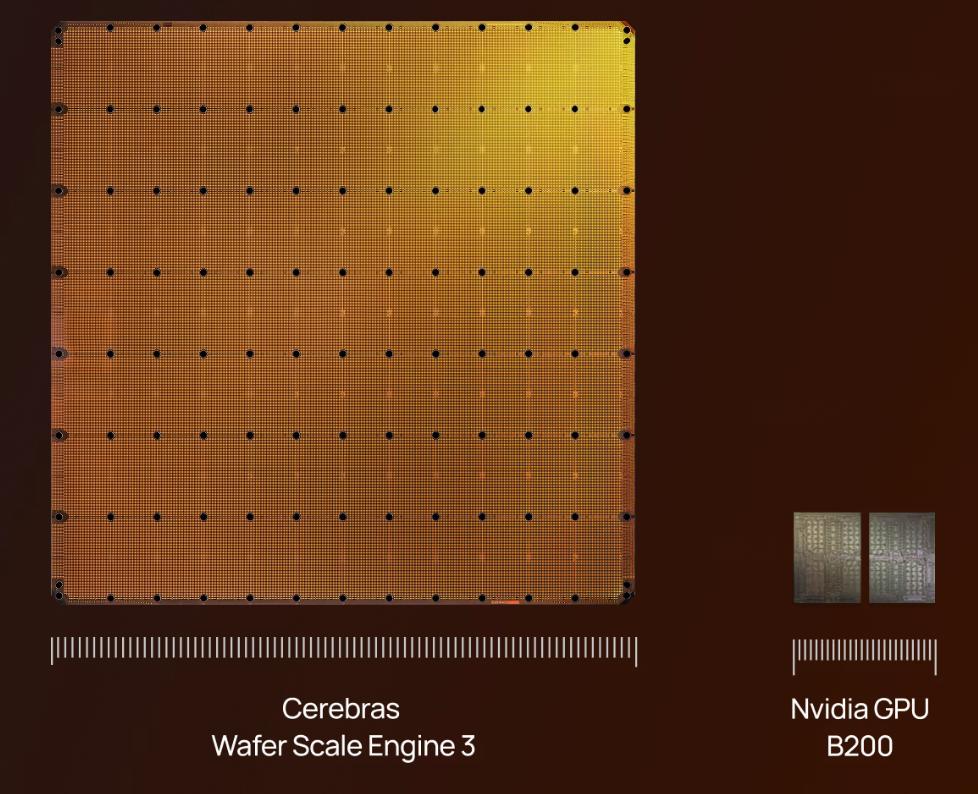
Di solito i chip per computer che incontriamo hanno le dimensioni di un'unghia, anche le GPU sono grandi quanto un palmo. Ma una società californiana chiamata Cerebras ha creato un chip che somiglia a un grande piatto, con un diametro superiore a 200 millimetri, una superficie di 46.225 millimetri quadrati e integra 4 trilioni di transistor.
Questa azienda è stata quotata al Nasdaq il 14 maggio 2026, con un prezzo di emissione di 185 dollari, prezzo d'apertura a 350 dollari e una crescita del 89% nel primo giorno, raggiungendo una capitalizzazione di mercato di 75 miliardi di dollari. Dei cinque co-fondatori, quattro provengono da una società di server acquisita da AMD, SeaMicro, l'altro dal MIT. Hanno lavorato silenziosamente dal 2015 per quasi dieci anni e ora, con il loro chip a livello di wafer, sono in prima linea nella corsa alla potenza di calcolo per l'AI.

(Fonte: cerebras.ai)
Il prodotto di punta di Cerebras si chiama Wafer Scale Engine e ha già raggiunto la terza generazione, WSE-3. Tradizionalmente, dopo la fabbricazione, un wafer viene tagliato in centinaia di piccoli chip, Cerebras fa il contrario: non taglia il wafer, ma lo trasforma direttamente in un unico, grande chip.Questo wafer integra 84 "die" virtuali, ognuno con circa 10.700 core, per un totale di 900.000 core di calcolo sull'intero chip.
Questi core sono collegati da una rete on-chip a griglia 2D; ogni core è dotato di un router a cinque porte che supporta la trasmissione dati in quattro direzioni e operazioni locali di lettura/scrittura. La banda di memoria totale del chip raggiunge i 21 petabyte al secondo, mentre quella della rete on-chip arriva a 214 petabyte al secondo.

(Fonte: cerebras.ai)
Il chip WSE-3 è prodotto con il processo a 5 nanometri di TSMC, ogni core occupa circa 38.000 micrometri quadrati, di cui metà dedicata alla SRAM locale da 48KB e l'altra metà ai circuiti logici. La SRAM totale del chip raggiunge i 44GB. Tutta la memoria è distribuita vicino ai core, con una distanza fisica di appena decine di micrometri tra memoria e unità di calcolo, senza necessità di accedere alla memoria HBM esterna ad alta banda come le GPU tradizionali. Cerebras sostiene che, a parità di superficie di silicio, la loro banda di memoria è circa 200 volte quella di una GPU.

(Fonte: cerebras.ai)
Questa architettura è particolarmente adatta per gestire la sparsità non strutturata delle reti neurali. Le GPU tradizionali eseguono i calcoli indipendentemente dal fatto che i pesi siano zero o meno; Cerebras, invece, filtra gli zeri già alla fonte, inviando tramite la rete on-chip solo i dati non nulli al rispettivo core di calcolo.Ogni pacchetto dati contiene 16 bit di dati e 16 bit di informazioni di controllo; appena ricevuti, il core esegue automaticamente un'operazione di moltiplicazione e addizione. Questo metodo evita molti calcoli inutili, accelerando notevolmente i modelli con un'elevata sparsità.
Secondo il white paper tecnico dell'azienda, per operazioni BLAS inferiori alla moltiplicazione di matrici generali, come il prodotto matrice-vettore o vettore-scalare, i chip tradizionali non riescono a lavorare al massimo per limitazioni di banda della memoria. L'architettura di Cerebras, invece, grazie alla banda di memoria elevata, mantiene un alto tasso di utilizzo.
(Fonte: cerebras.ai)
Un'altra tecnologia fondamentale di Cerebras è chiamata Weight Streaming: durante l’addestramento di grandi modelli, i pesi non sono memorizzati sul chip, ma in un dispositivo esterno chiamato MemoryX, e vengono trasmessi in streaming al chip WSE-3 su richiesta. Per ogni layer della rete, i pesi sono letti dalla DRAM e dalla memoria flash esterne e inviati ai core tramite le interfacce input/output del chip.
Appena i pesi arrivano al core, vengono moltiplicati in blocco per i valori di attivazione locali; terminato il calcolo, i pesi vengono scartati e non rimangono sul chip. Questo metodo permette di non essere limitati dalla capacità della memoria interna e consente l'addestramento di modelli con trilioni di parametri.

(Fonte: cerebras.ai)
Sul lato software, Cerebras mette a disposizione toolchain di compilazione complete che possono mappare automaticamente i modelli sviluppati con PyTorch o TensorFlow sui 900.000 core disponibili. Per i modelli di classe Transformer, i tensori di attivazione hanno tre dimensioni: batch size, sequenza e dimensione nascosta. Il compilatore divide la dimensione nascosta sull’asse X del chip, mentre batch size e lunghezza della sequenza vengono divisi sull’asse Y.
Durante i calcoli di moltiplicazione di matrici, i pesi vengono trasmessi per riga a tutte le colonne dei core corrispondenti, attivando i calcoli di moltiplicazione e addizione, quindi le somme parziali vengono ridotte nella direzione delle colonne, e i risultati finali rimangono sul chip pronti per i calcoli del layer successivo. Tutta la schedulazione è configurata staticamente e le istruzioni vengono caricate tutte prima dell’esecuzione, senza variazioni durante il run.

(Fonte: cerebras.ai)
I cinque co-fondatori di Cerebras hanno una profonda esperienza in chip e sistemi.
Il CEO Andrew Feldman si è laureato a Stanford; la sua precedente azienda di microserver, SeaMicro, è stata acquisita da AMD per 357 milioni di dollari.
Il CTO Sean Lie ha conseguito laurea e master in ingegneria elettronica e informatica al MIT; in SeaMicro era architetto per IO virtualization e dopo l’acquisizione è diventato Fellow in AMD.
L’architetto di sistema Jean-Philippe Fricker ha un master presso l’EPFL di Losanna, e ha ricoperto ruoli nell’architettura hardware presso DSSD, SeaMicro, Alcatel-Lucent e Riverstone Networks.
Il Chief Architect per le tecnologie avanzate, Michael James, ha tre lauree presso UC Berkeley in neurobiologia molecolare, matematica e informatica, occupandosi di software per sistemi distribuiti in SeaMicro.
L’ex CTO onorario in pensione, Gary Lauterbach, detiene più di 50 brevetti, è stato Distinguished Engineer in Sun Microsystems e ha guidato la progettazione degli UltraSPARC III e IV.
Il modello di business di Cerebras è focalizzato sulla vendita del sistema completo CS-3, progettato attorno al chip WSE-3, installabile su rack standard dei data center. I clienti sono principalmente istituti di ricerca e aziende, tra cui G42 degli Emirati Arabi Uniti e la Mohamed bin Zayed University of Artificial Intelligence. Secondo quanto dichiarato al momento della quotazione, nel 2025 Cerebras ha realizzato un fatturato di 510 milioni di dollari, di cui il 24% da G42 e il 62% da MBZUAI. Il profitto netto annuale è stato di 238 milioni di dollari, contro una perdita di 482 milioni dell’anno precedente, passando così a un esercizio in attivo.
Cerebras aveva tentato la quotazione già nel 2024, quando i ricavi erano fortemente dipendenti dal solo cliente G42, che allora rappresentava l’87% degli introiti. Dato che le transazioni con soggetti degli Emirati richiedono l’approvazione del CFIUS, la domanda di quotazione era stata ritirata nonostante l’ok finale. In questa nuova IPO, la concentrazione dei clienti è migliorata, con il principale (MBZUAI) che pesa il 62%, ma i primi due clienti insieme fanno ancora l’86% dei ricavi, mantenendo criticità di rischio.
La strategia tecnologica di Cerebras è unica nel panorama dei chip per l’intelligenza artificiale. Altri competitor tendono a ispirarsi alle GPU, con molti piccoli core e memoria HBM. Cerebras affronta il problema con un enorme wafer monolitico. Questa soluzione ha vantaggi significativi nei calcoli sparsi e nell’inferenza di grandi modelli, ma pone anche sfide in termini di costi e rendimento produttivo.
Su un wafer così grande basta un solo difetto critico per compromettere l'intero chip: Cerebras risolve includendo collegamenti ridondanti e meccanismi di autocorrezione degli errori. Anche consumo e raffreddamento sono sfide ingegneristiche; il sistema CS-3 adotta un raffreddamento a liquido specificamente progettato.
Con OpenAI, Anthropic, SpaceX e altre società di AI pronte alla quotazione, la filiera dei chip per AI è sempre più al centro dell’attenzione dei mercati. Cerebras, come primo produttore puro di chip AI a sbarcare al Nasdaq, ha dato un segnale positivo a tutto il settore con una crescita del 89% nel primo giorno di contrattazione.
Tuttavia, la competizione nel mercato dei chip AI è sempre più serrata: oltre a NVIDIA, anche AMD, Intel e molte startup stanno lanciando nuovi prodotti. Resta da vedere se la soluzione wafer-scale di Cerebras riuscirà ad affermarsi nel mercato principale del training AI; serviranno più clienti e più tempo per avere la risposta definitiva.
Esclusione di responsabilità: il contenuto di questo articolo riflette esclusivamente l’opinione dell’autore e non rappresenta in alcun modo la piattaforma. Questo articolo non deve essere utilizzato come riferimento per prendere decisioni di investimento.
Ti potrebbe interessare anche
In tendenza
AltroIl vento contrario colpisce! L’inflazione fuori controllo alimenta le aspettative di una Fed "più alta e più a lungo", il prezzo dell’oro potrebbe chiudere in calo questa settimana
PEAQ fluttua del 54,6% nelle ultime 24 ore: volume di scambi in forte aumento guidato dalla collaborazione con CoinList per il "Initial Machine Offering"