
When engineers reject smarter models: The AI inference war, OpenAI switches to a new "weapon"

The artificial intelligence inference market is undergoing a profound paradigm shift—speed, rather than intelligence, is becoming the core variable developers are willing to pay for. This reversal of preference has thrust long-marginalized chipmaker Cerebras into the spotlight, and led OpenAI to spend tens of billions of dollars betting on a wafer-scale chip manufacturer that is about to go public.
According to an in-depth report by industry research firm SemiAnalysis, OpenAI has signed a master agreement with Cerebras for a total computing power of up to 750 megawatts, with potential expansion to 2 gigawatts, corresponding to remaining performance obligations worth $24.6 billion.
The core logic of this deal is: OpenAI’s GPT-5.3-Codex-Spark model can achieve generation speeds of 2,000 tokens per second per user on Cerebras hardware, far surpassing the interactive experience provided by HBM-based GPU clusters. Meanwhile, Cerebras stands at the threshold of an IPO, its fate now deeply tied to that of OpenAI.
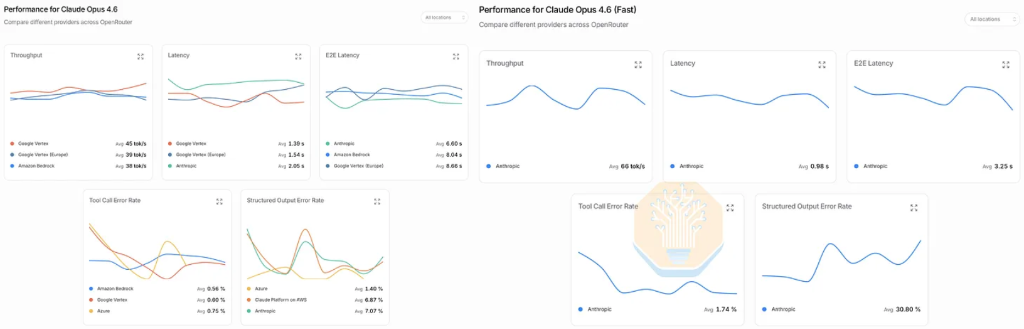
The market signals of this speed revolution are already clear. SemiAnalysis disclosed that 80% of its team's AI spending (with an annualized peak of $10 million) is concentrated on Anthropic’s Opus 4.6 fast mode—which trades a 6x price premium for 2.5x faster interaction speed. Even more convincing, when Opus 4.7 was released, several engineers on the team refused to upgrade simply because the new version didn’t support fast mode. This marked the first time the SemiAnalysis team had actively chosen faster token generation over cutting-edge intelligence.
Speed Premium: Developers Vote with Their Wallets
The competitive landscape of the inference market is being redrawn along a new axis.
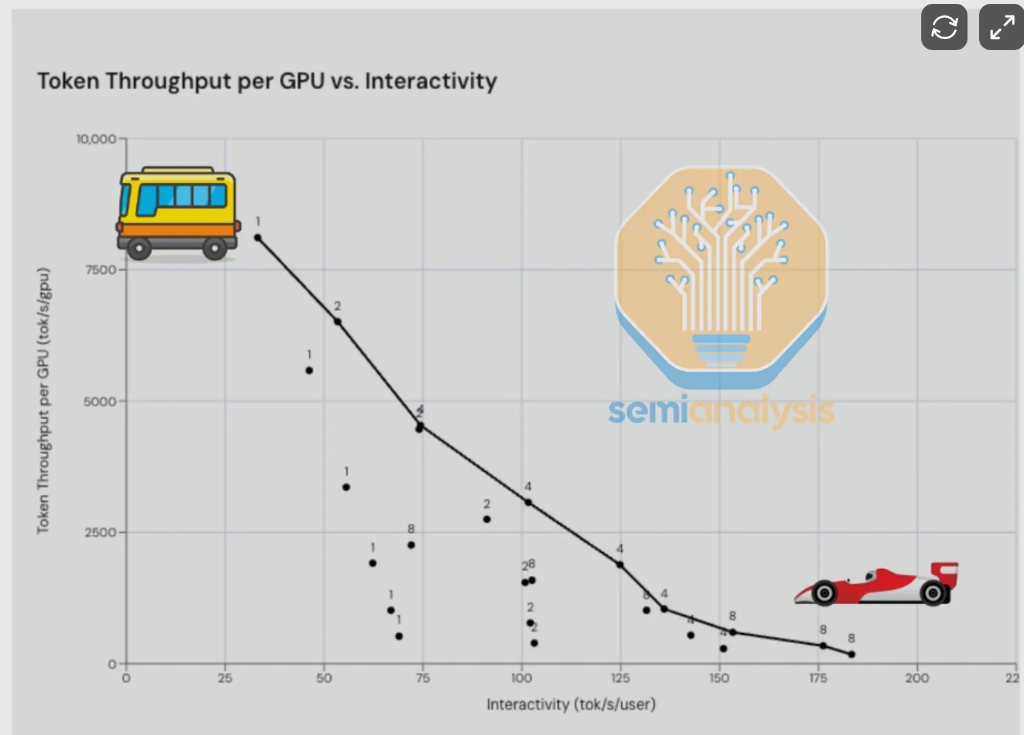
As Nvidia CEO Jensen Huang repeatedly emphasized at this year’s GTC conference, throughput (tokens per second per GPU) and interactivity (tokens per second per user) are the fundamental trade-offs in inference—the former serves batch processing, while the latter determines user experience. SemiAnalysis likens this to a choice between a "bus and a Ferrari": you can serve many users slowly, or serve a single user quickly.
The market’s preference has already been validated by consumer behavior. The Opus 4.6 fast mode, offering 2.5 times faster interaction at 6 times the price, once became Anthropic’s most profitable product SKU and was a key driver of its explosive ARR growth this year. However, data collected by SemiAnalysis in collaboration with OpenRouter shows that this mode has recently suffered performance degradation—standard Opus 4.6 maintains a stable interaction speed at about 40 tps, while the fast mode, which once exceeded 100 tps, has recently dropped to around 70 tps, reducing the actual acceleration ratio from 2.5x to about 1.75x.
Both OpenAI and Anthropic have recognized this stratification in demand and are using fast modes, priority modes, tiered pricing, and other product forms to try to cover the market and find profit-maximizing combinations.
Wafer-Scale Chips: The Technical Logic Behind a Bold Bet
Cerebras’ core gamble is to break through the physical limits of single-exposure lithography and turn an entire wafer into a single chip.
Its third-generation product, the WSE-3, is manufactured using TSMC’s N5 process and integrates 44GB SRAM on a single wafer, offering 21PB/s of memory bandwidth—thousands of times higher than HBM. The essence of this architecture is trading extremely high memory bandwidth for extremely low memory access latency, enabling WSE-3 to fully utilize its theoretical compute power in small batch, low arithmetic intensity decoding scenarios, whereas HBM-based GPUs in similar scenarios often suffer from "compute starvation."
However, this architecture comes at a significant cost in compute density. SemiAnalysis points out that the actual dense FP16 compute power of the WSE-3 is just 15.625 PFLOPS—eight times lower than the 125 PFLOPS Promoted by Cerebras. This difference is due to the use of an 8:1 unstructured sparsity assumption, something SemiAnalysis terms the "Feldman formula," comparing it to Nvidia’s "Jensen Math" but contending that the former goes even further.
On the cost side, SemiAnalysis estimates the bill of materials for each CS-3 server (including KVSS CPU nodes) is around $450,000, much higher than the roughly $20,000 TSMC wafer cost of the silicon alone. Expensive custom power modules (from Vicor), liquid cooling systems, and the need for custom reticles for each batch of wafers collectively boost the overall cost structure.

Architectural Shortcoming: The Geometric Challenge of Network Bandwidth
The most prominent weakness of the WSE-3 is its extremely limited off-chip bandwidth.
Each WSE-3 provides just 150GB/s (1.2Tb/s) off-chip bandwidth, only one-sixth of the 900GB/s scale-out bandwidth of a single Nvidia Blackwell NVLink5 GPU. This limitation is not a design oversight but an inherent constraint of wafer-scale architecture—SemiAnalysis calls it the "island problem."
The root of the issue lies in the uniform step-and-repeat exposure mechanism for wafers. The WSE-3 consists of 84 identical exposure units (dies) stitched together; each must be exactly alike so the on-die 2D mesh interconnects work across dies. This means it’s impossible to concentrate SerDes PHYs at the edge of the wafer—to increase I/O bandwidth, PHY area must be reserved in every exposure unit, but PHYs located in the interior cannot connect to the outside, creating large amounts of "stranded silicon." Additionally, PHY modules create "holes" in the mesh, increasing data routing latency and undermining the core advantage of wafer-scale architecture.
This bandwidth bottleneck directly limits Cerebras’ ability to serve large models. For modern agent workloads with more than 1 trillion parameters and million-token-level context windows, Cerebras has to use pipeline parallelism, splitting models across multiple wafers and only transmitting activations between wafers. As models scale up, the number of wafers required increases linearly, and the fixed latency of each inter-wafer transfer accumulates, ultimately eroding the speed advantage.
SRAM Scaling is Dead: Roadmap Worries
Another structural challenge facing Cerebras is the physical limit of SRAM density scaling.
From WSE-1 (TSMC 16nm, 18GB SRAM) to WSE-2 (7nm, 40GB), SRAM capacity achieved 2.2x generational growth. But from WSE-2 to WSE-3 (7nm to 5nm), SRAM increased from 40GB to just 44GB—a mere 10% increase, while logic transistor count grew by about 50%. SemiAnalysis data shows that after 5nm, TSMC’s N3E offers almost no SRAM cell area reduction compared to N5, and the same is true for N2 and subsequent nodes—SRAM scaling has essentially stalled.
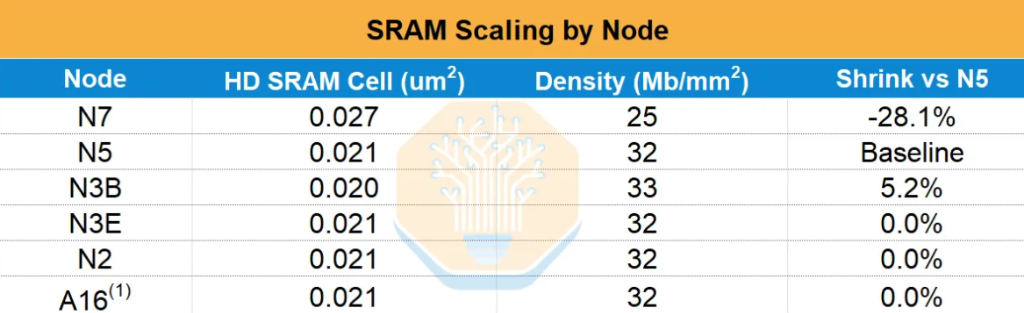
This means the only way for Cerebras to increase SRAM capacity in the future is to sacrifice logic area for memory within the same fixed wafer area—a strict zero-sum trade-off. The next-generation CS-4 system will continue to use the N5-based WSE-3, increasing power consumption to push clock speeds and compute, but SRAM capacity will remain unchanged.
By contrast, after Nvidia’s Groq acquisition, they can stack SRAM chips vertically using hybrid bonding (the LP40 roadmap), bypassing the limits of planar scaling. Cerebras is also exploring a similar path—using hybrid bonding to stack DRAM wafers or photonic interconnect wafers atop the WSE, but SemiAnalysis is cautious about its technical feasibility and timetable, suggesting the thermal-mechanical stress and bonding wave challenges of wafer-scale hybrid bonding are far greater than in conventional chips.
OpenAI Deal: The Double-Edged Sword of a Single Customer
The relationship between Cerebras and OpenAI goes far beyond that of a typical supplier and customer.
According to the S-1 filing cited by SemiAnalysis, the two parties signed a Master Relationship Agreement (MRA) in December 2025, with OpenAI committing to buy 750 megawatts of AI inference compute in stages from 2026 to 2028, with each batch contracted for 3–4 years (extendable to 5 years), plus an option to purchase an additional 1.25 gigawatts. As of December 31, 2025, Cerebras’ remaining performance obligations reached $24.6 billion.
On the capital structure side, OpenAI plays three roles: it provides Cerebras with a $1 billion secured revolving credit facility (6% annual interest, which is waived if repaid via compute delivery); it holds 33.445 million non-voting Class N common stock warrants with an exercise price near zero; and may hold about 12% of Cerebras shares on a fully-diluted basis. If the MRA is terminated for reasons other than OpenAI’s, Cerebras must immediately repay the entire loan balance and accrued interest, and OpenAI gains direct control over the use of escrow funds.
This structure means that Cerebras’ growth prospects are highly tied to a single customer. SemiAnalysis forecasts that in the coming years, Cerebras’ revenue will show a marked inflection point, with OpenAI as the main growth driver, but execution risks are equally concentrated—by 2028, the number of servers Cerebras must deliver will be an order of magnitude higher than its historical cumulative shipments, with data center capacity completion the largest uncertainty.
Trading Speed for Intelligence: What’s This Deal Worth?
OpenAI’s flagship product running on Cerebras, GPT-5.3-Codex-Spark, is not the true GPT-5.3-Codex, but a smaller model distilled from GPT-5.3-Codex and based on the gpt-oss-120B architecture, with parameter count more than 10x smaller than the original.
SemiAnalysis is blunt: at present, the Cerebras chip is only economically effective at serving relatively small models. For advanced workloads with over a trillion parameters and 1 million token context windows, if OpenAI wants to run them on Cerebras, it will have to accept significant cost premiums and the actual interactive speed is expected to fall below 1,000 tokens per second.
However, there is a key variable behind this assertion: the speed of algorithmic progress. SemiAnalysis believes that it may be less than a year before a 120B parameter model reaches GPT-5.5-level intelligence. At that point, the value proposition of "trading cutting-edge intelligence for instant token generation" will be fundamentally transformed—just as today engineers are willing to forsake the higher intelligence of Opus 4.7 for the interactive experience of Opus 4.6 fast mode.
The initial 750 megawatt commitment is now locked in. The real question is: when the 120B model’s intelligence matches today’s state-of-the-art, will OpenAI choose to exercise its option and expand the deal to 2 gigawatts or more? The answer will determine whether Cerebras can fulfill its IPO valuation—and will define the direction of the next battle in the inference wars.
Disclaimer: The content of this article solely reflects the author's opinion and does not represent the platform in any capacity. This article is not intended to serve as a reference for making investment decisions.
You may also like
Bitcoin, Ethereum ETFs Bleed as Crypto Funds Shed $1.07 Billion, Ending 6-Week Win Streak
AIA fluctuates 41.1% within 24 hours: speculative trading dominates, no clear single event driving the movement