摩根士丹利重磅研報:AI智能體的崛起:全球影響,瓶頸為什麼從GPU轉到了CPU?

今天要和大家拆解的,是摩根士丹利4月19日發佈的一篇重磅報告——《Rise of the AI Agent – Global Implications》,原文73頁。

這篇研報的核心結論只有一句話:AI基礎設施的下一階段,瓶頸不再是GPU,而是CPU、記憶體、基板和設備。
如果你覺得這句話聽起來有點反直覺,那就對了。過去兩年,整個市場的敘事都是「Nvidia、HBM、台積電」,GPU是絕對的主角。但摩根士丹利這次換了一個視角——當AI從「生成」走向「自主行動」(也就是Agentic AI,智能體AI),系統真正的瓶頸正從算力本身,轉移到「協調算力」這件事上。
而「協調」這件事,不歸GPU管,歸CPU管。
一、從「生成」到「行動」,工作量被重新分配
摩根士丹利把智能體AI拆成了三個支柱:大腦(LLM,跑在GPU上)、調度(Orchestration,跑在CPU上)、知識(Memory,跑在記憶體和儲存上)。

生成式AI時代,用戶問一個問題,GPU吐出一個答案,流程簡單,CPU只是「輔助」角色。但智能體AI不一樣——它要規劃任務、調用外部API、檢索數據、執行代碼、再反思結果、必要時循環迭代。Nvidia CEO黃仁勳在今年3月的GTC 2026上說了一句很精確的話:CPU不再只是支持模型,它在驅動模型。
摩根士丹利援引喬治亞理工和Intel的聯合研究指出:在智能體工作負載中,CPU端處理占端到端延遲的比例可以高達50%到90%。換句話說,GPU很多時候是「空等CPU把活幹完」。這個數字如果成立,意味過去幾年所有關於GPU利用率的假設都要重新計算。
二、CPU的增量市場有多大
摩根士丹利給出了一個全新的預估框架,把數據中心CPU分成三類:
第一類是頭節點CPU(Head Node),就是直接掛在GPU機架上的CPU,像是Nvidia Grace、Vera。假設到2030年全球部署500萬顆AI加速器,每個GPU板配兩顆高階CPU,單顆均價5000美元,這部分TAM約500億美元。
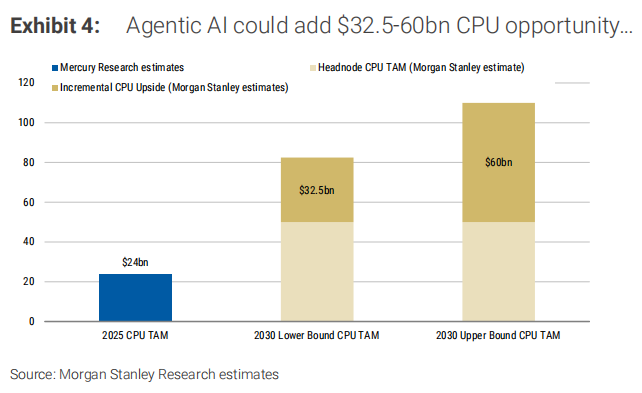
第二類是調度CPU(Orchestration),這是智能體AI全新新增的需求。摩根士丹利假設每個GPU需要2-3顆額外的CPU-heavy節點,核心數從現在的136核(Arm AGI CPU)漲到2030年的200-300核,單顆均價3000美元。這部分TAM在300-450億美元之間。
第三類是儲存節點和網路節點上的其他CPU,TAM約為25-150億美元。
三類加起來,2030年數據中心CPU總市場規模將達到825億到1100億美元,其中智能體AI直接貢獻的增量是325億到600億美元。
如果按Nvidia黃仁勳「2030年AI基礎設施投資3-5萬億美元」的更激進假設,CPU TAM甚至有可能衝到2000-4500億美元。
三、記憶體重估:DRAM從被動儲存變主動元件
這是整篇研報最讓我覺得有意思的部分。
Sam Altman說過一句話:「AI真正的突破不是更好的推理,而是持久的記憶。」摩根士丹利把這句話翻譯成了產業語言——智能體AI的競爭力,正從「模型效能」轉向「上下文記憶能力」。
因為智能體要連續運行、跨會話保留狀態、在多個agent之間共享記憶、從過去的互動中學習。這代表記憶體不再是GPU旁的被動快取,而是一個獨立的、持續活躍的系統層。
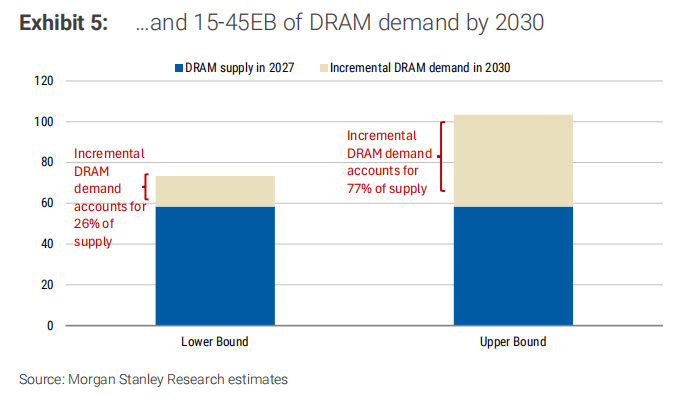
摩根士丹利估算,到2030年智能體AI將帶來15-45 EB(艾位元組)的增量DRAM需求,這個數字大約是2027年全年DRAM供應的26%到77%。注意,這是在HBM之外的純CPU端DRAM需求。
具體路徑是:Nvidia Vera CPU單顆支援1.5TB LPDDR5X記憶體,整機櫃可達400TB;AMD EPYC 9005單顆支援6TB DDR5,加上CXL擴充可到8TB。摩根士丹利假設到2030年,每顆調度CPU平均掛載1.5TB(基礎場景)到3TB(樂觀場景)DRAM,乘以1000-1500萬顆新增CPU,就是這個量級的需求。
四、ABF基板:一個被低估的結構性週期
ABF基板曾經是一個PC驅動的週期性產業——2015年PC占整個ABF需求的70%。但摩根士丹利認為,到2030年,伺服器CPU、GPU、ASIC、網路晶片加起來將占ABF終端需求的75%以上。
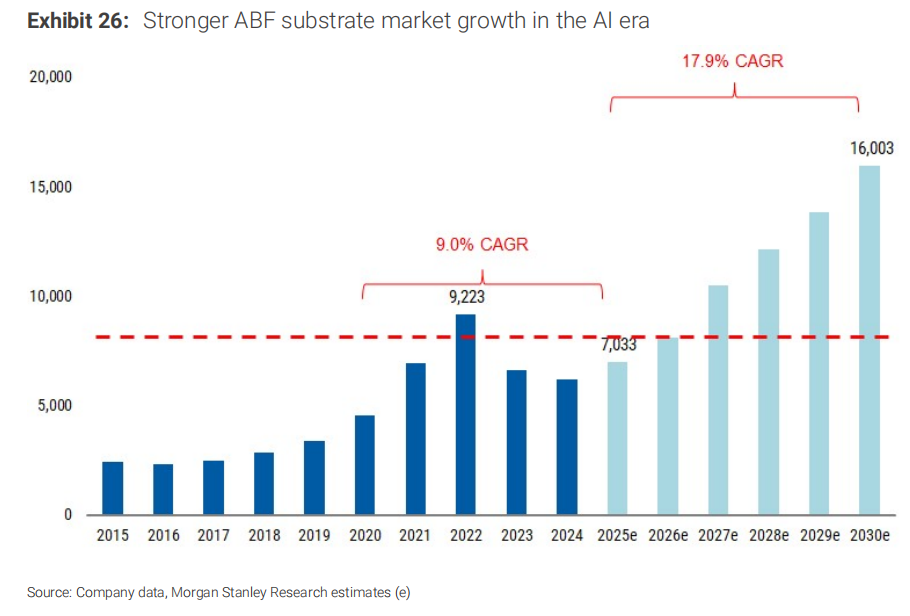
更關鍵的數字是成長速度。摩根士丹利把ABF基板市場2025-2030年的年複合增長率,從原來的16.1%上調到17.9%,對比2020-2025年的9.0%,這是一個決定性的提速。供需缺口方面,如果沒有新增產能,智能體AI帶來的增量CPU需求將把2030年的供需缺口從原來的7%擴大到15%。
這代表ABF供應商在未來幾年不只可以漲價,而且漲價不是靠博弈,而是靠「能生產多少賣多少」的結構性短缺。
五、具體標的:摩根士丹利的四個關鍵上調
摩根士丹利這次同時上調了四家公司的目標價:
SK海力士從130萬韓元上調到170萬韓元,2026-2028年EPS預測分別上調24%、37%、78%。
三星電子從25.1萬韓元上調到36.2萬韓元,2026-2028年EPS預測上調45%、74%、121%。
三星機電(SEMCO)從50萬韓元上調到71萬韓元,核心邏輯是MLCC和ABF雙AI敞口。
這裡面最有意思的其實是三星電子。摩根士丹利說,三星的HBM改善+商品記憶體超級週期+LTA長約鎖價,這三個因素疊加起來,讓市場對三星的獲利預期嚴重落後。2027年預測本益比只有5倍。
美股這邊,摩根士丹利明確表態:「我們偏好透過AI賦能者(Nvidia、Broadcom、美光、SanDisk)來布局智能體AI敞口,而不是直接買CPU的Intel和AMD。」理由很簡單——CPU股(Intel、AMD)的估值是23-64倍本益比,而Nvidia只有18倍FY27預估本益比,記憶體股只有5-9倍本益比。
CPU故事最純粹的受益者是AMD(雲CPU市占率已超越Intel達到53%),但摩根士丹利認為AMD的股價更多綁定GPU故事,而Intel更多綁定代工故事,所以兩家都給Equal-weight。真正純粹的AI賦能敞口反而是在記憶體和GPU龍頭身上。
我的理解:
這份研報最有價值的地方,不是那些具體的TAM數字,而是它換了一個分析AI產業鏈的座標系。
過去兩年市場的思維模式是「算力稀缺→買GPU→買HBM→買台積電」,這是一條單線邏輯。但當AI開始「自主行動」,問題就變成了:誰來協調這一切?誰來記住上下文?誰來在數千個agent之間傳遞狀態?
答案不再是一顆晶片,而是一整個系統。CPU、DRAM、ABF、基板、MLCC、BMC、CPU socket、電源管理、散熱——這些過去被認為是「配角」的環節,現在每一項都正被智能體AI重新定價。
對一般投資者來說,這意味著兩件事。
第一,Nvidia敘事之外,還有一大批「隱形受益者」值得研究。 摩根士丹利列出的清單很長:三星機電和Ibiden的ABF基板、Unimicron的CPU基板、Aspeed的BMC(全球CPU伺服器BMC市占率70%)、Montage的記憶體介面(全球市占率36.8%)、Yageo的MLCC、Lotes和FIT的CPU socket、ASML的EUV光刻、KLA的量測設備。這裡的每一個環節,都不是泡沫級估值,但成長曲線正被智能體AI重新定義。
第二,週期型品種的週期正被結構性拉長。 以ABF基板為例,歷史上這是一個典型的週期性行業,跟著PC和伺服器走,三至四年一循環。但如果摩根士丹利的判斷正確——AI驅動的ABF上行週期能持續到2030年——那麼市場對這類標的應該用「結構性成長股」的估值邏輯,而不是「週期股」的估值邏輯。這種邏輯切換本身,就是估值重估的驅動力。
當然,所有這些判斷都建立在一個前提之下:智能體AI真的會按照摩根士丹利描繪的路徑擴散開來。這條路徑的關鍵節點是2026-2027年企業端的Agent部署,以及長約(LTA)能否在2027年真正鎖住記憶體和基板的價格。如果這兩件事兌現了,這份研報就是一張不錯的路線圖。
免責聲明:文章中的所有內容僅代表作者的觀點,與本平台無關。用戶不應以本文作為投資決策的參考。
您也可能喜歡
美債,大消息!金價銀價重挫,滬金瞬時大跌,疑現「烏龍指」,分析師:可能和美債有關
光大期貨0520黃金點評:通脹憂慮與鷹派預期施壓,金價短期維持偏弱格局

2026年FOMC票委保爾森「放鷹」:傾向於維持利率不變 降息前提��是抗通膨持續取得進展