
Cuando los ingenieros rechazan modelos más inteligentes: La batalla de inferencia en IA, OpenAI cambia de "arma"

El mercado de inferencia de inteligencia artificial está experimentando una profunda transformación de paradigma: la velocidad, y no la inteligencia, se está convirtiendo en la variable principal por la que los desarrolladores están dispuestos a pagar. Este cambio de preferencia ha llevado a la empresa de chips Cerebras, por mucho tiempo en los márgenes, al centro de atención, y ha motivado a OpenAI a apostar decenas de miles de millones de dólares en un fabricante de chips a nivel de oblea que está a punto de salir a bolsa.
Según un informe detallado de la consultora del sector SemiAnalysis, OpenAI ha firmado un acuerdo principal con Cerebras por una potencia total de 750 megavatios de capacidad de inferencia, con una posible ampliación a 2 gigavatios, lo que representa obligaciones contractuales restantes por valor de 24.600 millones de dólares.
La lógica central de este acuerdo radica en que: el modelo GPT-5.3-Codex-Spark de OpenAI puede generar 2.000 tokens por usuario por segundo en el hardware de Cerebras, superando notablemente la experiencia interactiva que ofrecen los clústeres de GPU con HBM. Al mismo tiempo, Cerebras está al borde de su IPO, y su destino está profundamente entrelazado con OpenAI.
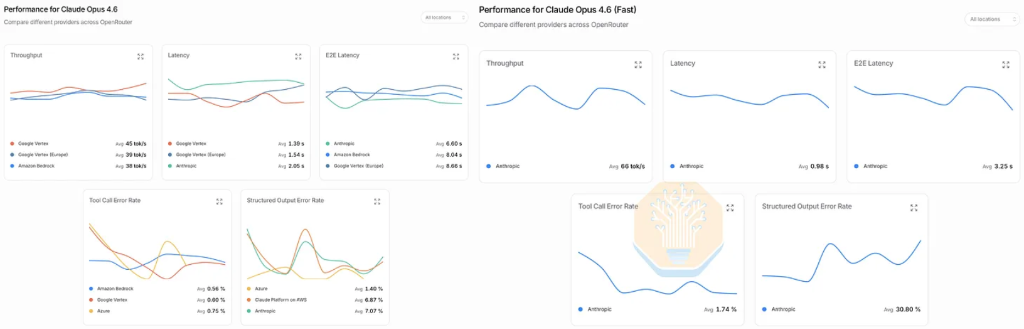
La señal de mercado de esta revolución de velocidad ya es bastante clara. SemiAnalysis revela que el 80% del gasto en IA de su equipo (con un pico anualizado de 10 millones de dólares) se concentra en el modo rápido de Opus 4.6 de Anthropic —este modo ofrece una experiencia de interacción 2,5 veces más rápida, a un precio seis veces mayor. Más aún, cuando se lanzó Opus 4.7, varios ingenieros del equipo se negaron a actualizarse porque la nueva versión no soporta el modo rápido. Es la primera vez que el equipo de SemiAnalysis renuncia activamente a la inteligencia de vanguardia en favor de una generación de tokens más rápida.
Prima de velocidad: los desarrolladores "votan" con su cartera
El panorama competitivo del mercado de inferencia se está redefiniendo a lo largo de un nuevo eje.
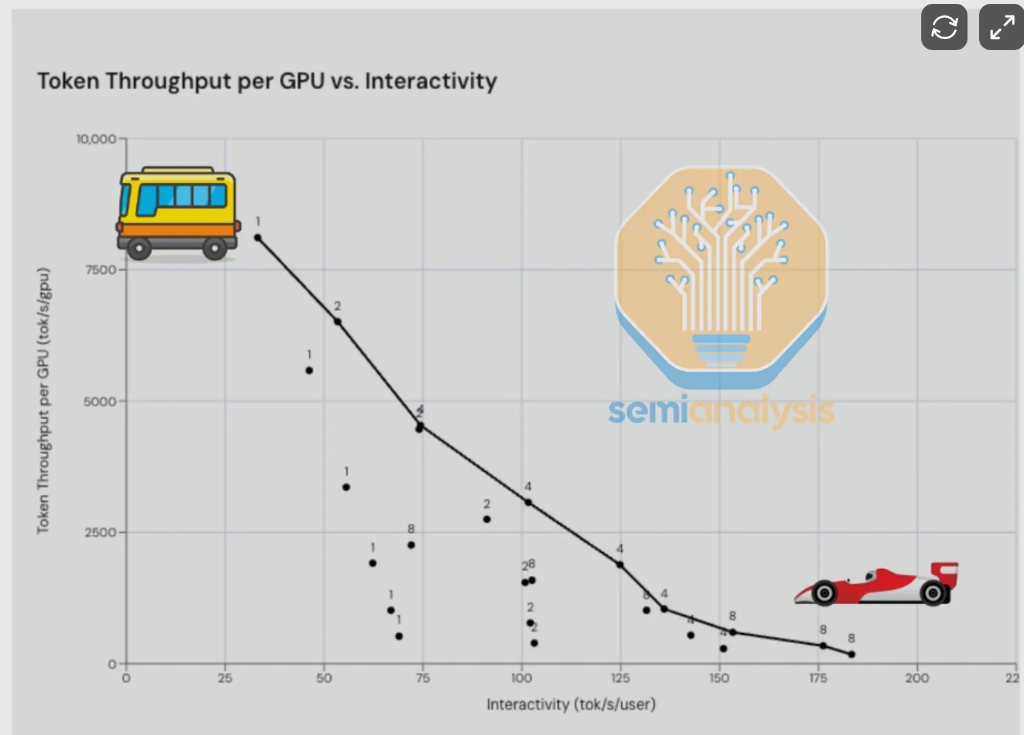
Como recalcó repetidamente Jensen Huang, CEO de Nvidia, en la conferencia GTC de este año, el rendimiento (tokens por GPU por segundo) y la interactividad (tokens por usuario por segundo) son un principio fundamental de la inferencia: el primero se centra en el procesamiento por lotes, mientras el segundo determina la experiencia del usuario. SemiAnalysis lo compara con elegir entre "un autobús y un Ferrari": puedes servir lentamenta gran cantidad de usuarios, o servir rápidamente a un solo usuario.
Las preferencias del mercado ya han sido validadas por el comportamiento de consumo. El modo rápido de Opus 4.6, que ofrece aproximadamente 2,5 veces la velocidad de interacción por un precio seis veces mayor, se convirtió en una de las SKU más rentables de Anthropic y un motor clave para el explosivo crecimiento anual del ARR de la empresa este año. Sin embargo, los datos recopilados por SemiAnalysis en colaboración con OpenRouter muestran que este modo ha experimentado recientemente un deterioro en el rendimiento: la velocidad de interacción de la versión estándar de Opus 4.6 se mantiene estable en unos 40 tps, el modo rápido superó los 100 tps en su momento, pero recientemente ha descendido a unos 70 tps, con la aceleración real reduciéndose de un factor de 2,5 a aproximadamente 1,75.
OpenAI y Anthropic ya son conscientes de esta segmentación de la demanda y, a través de diversos formatos de producto como el modo rápido, el modo prioritario y la tarificación por lotes, buscan cubrir todo el mercado y encontrar el máximo punto de rentabilidad.
Chips a nivel de oblea: la lógica tecnológica de una gran apuesta
La apuesta principal de Cerebras es superar los límites físicos de la exposición única de las máquinas de litografía y construir un chip a partir de toda una oblea.
Su producto de tercera generación, WSE-3, se fabrica con tecnología N5 de TSMC, integrando 44 GB de SRAM en una sola oblea y proporcionando un ancho de banda de memoria de 21 PB/s, miles de veces superior al de HBM. La esencia de esta arquitectura está en: ofrecer un altísimo ancho de banda de memoria a costa de una latencia de acceso bajísima, permitiendo que WSE-3 utilice todo su potencial teórico en escenarios de decodificación de lotes pequeños y baja intensidad aritmética, mientras que las GPU con HBM, bajo esas mismas condiciones, suelen encontrarse "hambrientas de potencia de cálculo".
Sin embargo, esta arquitectura conlleva notables costes en términos de densidad de cálculo. SemiAnalysis señala que el rendimiento de FP16 denso de WSE-3 es en realidad solo de 15,625 PFLOPS, ocho veces menor que los 125 PFLOPS promocionados oficialmente por Cerebras, debido a que han asumido una hipótesis de dispersión no estructurada 8:1. SemiAnalysis llama a esto la "fórmula Feldman" y la compara con la "matemática de Jensen" de Nvidia, aunque considera que la primera va aún más lejos.
En cuanto al coste del sistema, SemiAnalysis estima que el coste de materiales de cada servidor CS-3 (incluido el nodo CPU KVSS) ronda los 450.000 dólares, muy por encima del coste de la oblea de silicio de TSMC, que es de unos 20.000 dólares por chip. El elevado coste de los módulos de alimentación personalizados (de Vicor), los sistemas de refrigeración líquida y las máscaras personalizadas requeridas para cada lote de obleas elevan toda la estructura de costes.

Deficiencias arquitectónicas: el dilema geométrico del ancho de banda de red
La debilidad más notable del WSE-3 es su ancho de banda off-chip extremadamente limitado.
Cada WSE-3 solo ofrece 150 GB/s (1,2 Tb/s) de ancho de banda fuera del chip, que representa solo una sexta parte del ancho de banda de expansión de 900 GB/s por GPU de Blackwell NVLink5 de Nvidia. Esta limitación no se debe a un descuido de diseño, sino a una restricción inherente de la arquitectura a nivel de oblea; SemiAnalysis la llama "el problema de la isla".
La raíz del problema está en el mecanismo de exposición uniforme de la oblea. El WSE-3 está compuesto por 84 unidades idénticas de exposición (diedos) ensambladas, y cada una debe ser exactamente igual para garantizar que la interconexión 2D en el chip funcione correctamente entre dies. Esto significa que no se pueden colocar físicamente los SerDes PHY el borde de la oblea; para aumentar el ancho de banda de I/O, sería necesario reservar espacio en cada unidad de exposición, pero los PHY ubicados en el interior de la oblea no pueden conectarse al exterior, generando gran cantidad de "silicio varado". Además, los módulos PHY crean "huecos" en la malla del chip, aumentando la latencia del routing de datos y debilitando la principal ventaja de la arquitectura a nivel de oblea.
Esta limitación de ancho de banda condiciona directamente la capacidad de Cerebras para servir grandes modelos. En cargas modernas de trabajo de IA, con más de un billón de parámetros y ventanas de contexto de hasta un millón de tokens, Cerebras debe adoptar una paralelización en pipeline, dividiendo el modelo por capas entre varias obleas y transfiriendo solo los valores de activación entre obleas. Pero, a medida que crece el modelo, el número de obleas necesarias aumenta linealmente, y la latencia fija de cada transferencia inter-oblea se acumula, erosionando finalmente la ventaja de velocidad.
Expansión de SRAM: el futuro incierto del roadmap
Otro desafío estructural al que se enfrenta Cerebras es el límite físico para expandir la densidad de SRAM.
Del WSE-1 (TSMC 16nm, 18GB de SRAM) al WSE-2 (7nm, 40GB), la capacidad de SRAM se duplicó 2,2 veces entre generaciones. Pero de WSE-2 (7nm) a WSE-3 (5nm), la capacidad de SRAM solo subió de 40GB a 44GB (un aumento del 10%), mientras que el número de transistores lógicos creció alrededor de un 50%. Datos de SemiAnalysis muestran que, después del 5nm, el área de celda de SRAM del N3E de TSMC frente al N5 apenas presenta reducción, y tanto el N2 como los nodos posteriores muestran la misma inercia—la expansión de SRAM está prácticamente estancada.
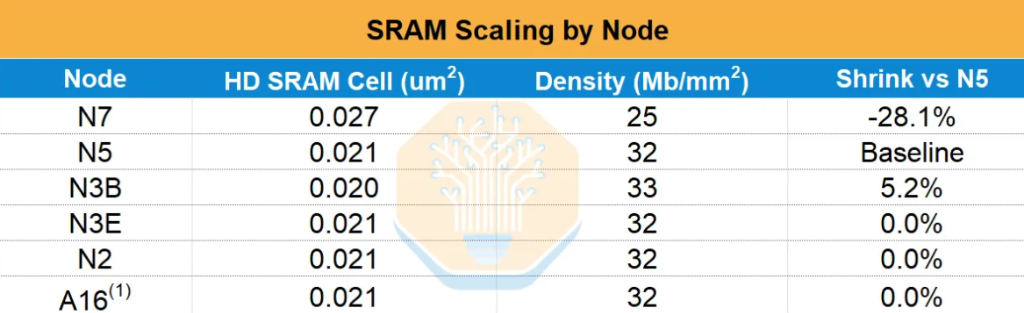
Esto significa que la única forma que tiene Cerebras de incrementar la capacidad de SRAM en el futuro será sacrificar área de cómputo para añadir almacenamiento dentro del tamaño fijo de la oblea, realizando un equilibrio estrictamente de suma cero. La próxima generación de sistemas CS-4 usará el WSE-3 de N5, manteniendo la capacidad de SRAM y solo elevando la frecuencia y la potencia a través de mayor consumo energético.
Por el contrario, tras la adquisición de Groq, Nvidia puede usar tecnología de bonding híbrido para apilar chips de SRAM verticalmente (vía el roadmap LP40), eludiendo la limitación de la expansión en plano. Cerebras también está explorando caminos similares—apilando obleas de DRAM o interconexión fotónica sobre el WSE mediante bonding híbrido—pero SemiAnalysis es cauteloso tanto con la viabilidad como con el calendario, y señala que los desafíos termomecánicos y de alineación del bonding a nivel de oblea son mucho mayores que en los chips convencionales.
El acuerdo con OpenAI: la espada de doble filo de un solo cliente
La relación entre Cerebras y OpenAI va mucho más allá de la de un simple proveedor y cliente.
Según documentos S-1 citados por SemiAnalysis, ambas partes firmaron en diciembre de 2025 un Acuerdo Maestro de Relación (MRA), por el cual OpenAI se compromete a comprar por lotes 750 megavatios de potencia de inferencia entre 2026 y 2028, con contratos por lote de entre 3 y 4 años renovables hasta 5, y una opción para comprar 1,25 gigavatios adicionales. Al 31 de diciembre de 2025, las obligaciones contractuales restantes para Cerebras alcanzaban los 24.600 millones de dólares.
Desde la óptica de la estructura de capital, OpenAI desempeña tres papeles: proporciona a Cerebras un préstamo de capital circulante garantizado de 1.000 millones de dólares (tipo de interés anual del 6%; si se paga en capacidad de cómputo, se exime el interés); retiene warrants sobre 33.445.000 acciones comunes de clase N (sin derecho a voto), con precio de ejercicio cercano a cero; y, sobre base totalmente diluida, podría poseer alrededor del 12% de las acciones de Cerebras. Si el MRA se rescindiera por causas ajenas a OpenAI, Cerebras tendría que reembolsar inmediatamente el saldo completo del préstamo más los intereses devengados, y OpenAI tendría derecho a controlar directamente el uso de fondos de las cuentas escrow.
Esta estructura implica que las perspectivas de crecimiento de Cerebras están fuertemente atadas a un solo cliente. SemiAnalysis prevé un punto de inflexión claro en los ingresos de Cerebras en los próximos años, siendo OpenAI el principal motor de crecimiento pero también el mayor riesgo operacional; hasta 2028, el número de servidores que Cerebras debe entregar superará en un orden de magnitud su historial de ventas acumuladas, y el progreso en la capacidad efectiva del data center es la mayor incertidumbre.
Intercambio de velocidad por inteligencia: ¿cuánto vale este acuerdo?
El producto insignia GPT-5.3-Codex-Spark que OpenAI ejecuta en Cerebras no es un GPT-5.3-Codex auténtico, sino un modelo pequeño basado en la arquitectura gpt-oss-120B, entrenado mediante distilación a partir de GPT-5.3-Codex, cuyo número de parámetros es más de 10 veces menor que el original.
SemiAnalysis lo deja claro: los chips de Cerebras solo son económicamente eficientes para servir modelos relativamente pequeños en la actualidad. Para cargas modernas superiores a un billón de parámetros y ventanas de contexto de un millón de tokens, si OpenAI quiere ejecutar estos escenarios en Cerebras, tendrá que aceptar una prima significativa en el coste, y la velocidad de interacción real probablemente será inferior a 1.000 tokens por segundo.
No obstante, hay una variable clave: el ritmo del progreso algorítmico. SemiAnalysis cree que podría faltar menos de un año para que un modelo de 120B parámetros alcance el nivel de inteligencia de un GPT-5.5. En ese momento, la propuesta de valor de "cambiar inteligencia de vanguardia por tokens ultrarrápidos" se transformará radicalmente—tal como hoy los ingenieros prefieren renunciar a la mayor inteligencia de Opus 4.7 y mantener la experiencia de Opus 4.6 en modo rápido.
El compromiso inicial de 750 megavatios ya está bloqueado. La verdadera cuestión es: cuando la inteligencia del modelo de 120B iguale el nivel de vanguardia actual, ¿OpenAI ejercerá su opción de compra y ampliará la escala del acuerdo a 2 gigavatios o incluso más? La respuesta a esta pregunta determinará si Cerebras puede hacer realidad la valoración de su IPO y definirá el resultado de la próxima fase de la guerra por la inferencia.
Disclaimer: The content of this article solely reflects the author's opinion and does not represent the platform in any capacity. This article is not intended to serve as a reference for making investment decisions.
You may also like

Trending news
MoreGran noticia sobre los bonos del Tesoro de EE.UU.! Los precios del oro y la plata se desploman, el oro de Shanghái cae bruscamente en un instante, se sospecha de un "dedo gordo". Analistas: podría estar relacionado con los bonos del Tesoro de EE.UU.
Informe diario de Bitget UEX|Trump afirma que la guerra terminará pronto; el rendimiento de los bonos estadounidenses a 30 años alcanza el nivel más alto desde 2007; Google I/O presenta nuevos productos de IA y el informe financiero de Nvidia llega esta noche (20 de mayo de 2026)