
Одна мікросхема замінює одну тарілку: найбільший в історії IPO AI-чипів! П’ятеро ветеранів чипіндустрії десять років робили ставку на вибух зростання обчислювальної потужності AI


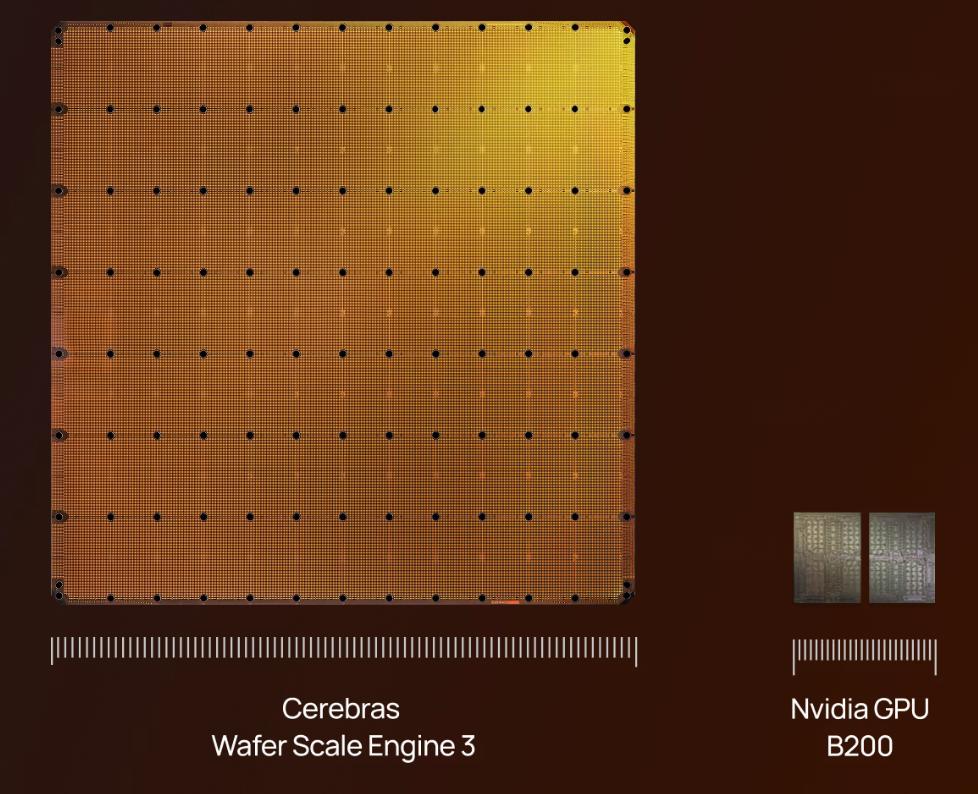
Зазвичай комп’ютерні чіпи мають розміри приблизно як нігтьова пластина, GPU – розміром з долоню, а компанія Cerebras з Каліфорнії, США, виготовила чіп розміром майже як велика тарілка, діаметр понад 200 мм, площа – 46 225 квадратних мм, інтегровано 4 трильйони транзисторів.
Ця компанія 14 травня 2026 року вийшла на Nasdaq, ціна розміщення – 185 доларів, ціна відкриття – 350 доларів, у перший день зросла на 89%, ринкова капіталізація досягла 75 млрд доларів. З п’яти співзасновників четверо раніше працювали в серверній компанії SeaMicro, яку придбала AMD, ще один – з MIT. Вони потай працювали з 2015 року майже десять років, і нині з чіпом на рівні пластини вийшли на перший план у змаганні за AI продуктивність.

(джерело: cerebras.ai)
Ключовий продукт Cerebras називається Wafer Scale Engine, вже створене третє покоління WSE-3. Традиційне виробництво чіпів полягає в розрізанні пластини на сотні маленьких чіпів, Cerebras робить навпаки – не розрізає, а використовує всю пластину як єдиний чіп.На цій пластині інтегровано 84 віртуальні кристали, кожна містить приблизно 10,700 ядер, загалом – 900 тисяч обчислювальних ядер.
Ядра з’єднані двовимірною сіткою всередині чіпа, кожне ядро має п’ятипортовий маршрутизатор, який підтримує передачу даних у чотирьох напрямках та локальні операції читання/запису. Пропускна здатність пам’яті всього чіпа – 21 петабайт/с, пропускна здатність внутрішньої мережі – 214 петабайт/с.

(джерело: cerebras.ai)
Чіп WSE-3 виготовлений за 5-нанометровим процесом TSMC, площа кожного обчислювального ядра – близько 38 тисяч квадратних мікрометрів, половина займає місцева SRAM пам’ять на 48 КБ, інша – логічні схеми. Загальний обсяг SRAM пам’яті усього чіпа – 44 ГБ. Уся пам’ять розташована поруч з ядром, відстань до обчислювального блоку – десятки мікрометрів, і немає потреби використовувати зовнішню пам’ять високої пропускної здатності (HBM) як у звичайних GPU. Cerebras стверджує, що за однакової площі кремнію вони мають пропускну здатність пам’яті приблизно в 200 разів більшу, ніж GPU.

(джерело: cerebras.ai)
Ця архітектура особливо підходить для обробки неструктурованої розрідженості нейромереж. Традиційний GPU виконує обчислення незалежно від того, чи дорівнює вага 0, а Cerebras фільтрує нульове значення вже на відправнику – лише ненульові дані передаються по внутрішній мережі у відповідне ядро.У кожному пакеті – 16-бітні дані й 16-бітна керуюча інформація, ядро автоматично запускає операцію множення-додавання по отриманих даних. Такий спосіб дозволяє уникнути великої кількості непотрібних обчислень і значно пришвидшує обробку дуже розріджених моделей.
Технічна біла книга компанії показує, що у випадку обчислень BLAS нижчого рівня ніж універсальне множення матриць, наприклад, множення матриці на вектор або вектора на скаляр, традиційні чіпи часто не можуть працювати на максимальній потужності через обмеження пропускної здатності пам’яті. Архітектура Cerebras завдяки високій пропускній здатності пам’яті дозволяє зберігати високий рівень ефективності.
(джерело: cerebras.ai)
Ще одна основна технологія Cerebras – Weight Streaming: при тренуванні великих моделей їхні ваги не зберігаються на чіпі, а виносяться на зовнішній пристрій MemoryX і потім потрібними потоками передаються до чіпа WSE-3. При обчисленні кожного шару мережі ваги беруться з зовнішньої DRAM або флеш-пам’яті і через інтерфейс чіпа потрапляють у ядра.
Як тільки вага потрапляє у ядро, її одразу використовують у пакетній операції множення-додавання із локальним значенням, і після завершення обчислення вагу відкидають, не зберігаючи на чіпі. Це дозволяє не обмежувати розмір моделі обсягом пам’яті чіпа і підтримувати моделі з трильйонами параметрів.

(джерело: cerebras.ai)
На програмному рівні Cerebras пропонує повний ланцюжок компіляторів, які можуть автоматично відображати моделі на PyTorch чи TensorFlow на 900 тисяч ядер. Для моделей типу Transformer тензор активації має три виміри: розмір пакету, довжина послідовності та прихований вимір. Компілятор розподіляє прихований вимір на X координату чіпа, а розмір пакету та довжину послідовності – на Y координату.
Коли виконується множення матриць, ваги по рядках розподіляють у відповідні колонки ядер, запускається операція множення-додавання, потім у напрямку колонок виконують часткову агрегатцію, і остаточний результат розподіляється по чіпу для підготовки до наступного шару. Усі обчислювальні задачі розподіляються статично, інструкції завантажуються разово перед запуском, у процесі виконання не змінюються.

(джерело: cerebras.ai)
Усі п’ять співзасновників Cerebras мають глибокий професійний досвід у сфері чіпів та систем.
Генеральний директор Andrew Feldman — випускник Стенфордського університету, раніше створив компанію мікросерверів SeaMicro, яку AMD придбала за 357 млн доларів.
Технічний директор Sean Lie має ступені бакалавра і магістра Массачусетського технологічного інституту з електроніки та комп’ютерних наук, працював архітектором IO в SeaMicro, після придбання AMD став академіком AMD.
Системний архітектор Jean-Philippe Fricker має ступінь магістра Федеральної політехнічної школи Лозанни, працював архітектором обладнання у DSSD, SeaMicro, Alcatel-Lucent і Riverstone Networks.
Головний архітектор з передових технологій Michael James має три ступені Каліфорнійського університету в Берклі – молекулярна нейробіологія, математика та комп’ютерні науки, відповідав за програмне забезпечення розподілених систем у SeaMicro.
Колишній технічний директор Gary Lauterbach, який вже на заслуженому відпочинку, має понад 50 патентів, був видатним інженером Sun Microsystems і очолював архітектурний дизайн мікропроцесорів UltraSPARC III та UltraSPARC IV.
Бізнес-модель Cerebras базується на продажу повних систем CS-3 – це повноцінна машина навколо чіпа WSE-3, яка може бути встановлена у стандартний серверний стелаж дата-центру. Клієнти – переважно науково-дослідні організації й підприємства, серед яких G42 (компанія з штучного інтелекту з ОАЕ) і Mohamed bin Zayed University of Artificial Intelligence. За даними IPO-документів, дохід Cerebras у 2025 році склав 510 млн доларів, частка G42 – 24%, MBZUAI – 62%. Чиста річна прибутковість – 238 млн доларів, компанія перейшла від збитку за попередній рік у 482 млн доларів до прибутку.
Cerebras намагалася вийти на IPO у 2024 році, але тоді її доходи сильно залежали від одного клієнта – G42, який забезпечував 87% прибутку. Оскільки ця інтеракція з компанією з ОАЕ підлягала перевірці Комітету з іноземних інвестицій США, компанія після отримання дозволу відкликала IPO-заявку. При повторному IPO концентрація на клієнтах вже покращилася, найбільший клієнт MBZUAI мав частку 62%, але два найбільші клієнти разом все ще забезпечують 86% доходу – ризик концентрації зберігається.
Технологічний підхід Cerebras у сфері AI-чіпів є унікальним. Більшість конкурентів наслідує архітектуру GPU – багато маленьких ядер та HBM-пам’ять, а Cerebras вирішила використати одну величезну пластину. Такий підхід має явні переваги для розріджених обчислень і великих моделей, але викликає виробничі труднощі — високі витрати й низька yield.
Вся пластина може втратити функціональність через одну фатальну помилку – Cerebras долає цю проблему за допомогою резервних зв’язків і автоматичних механізмів виправлення. Енергоспоживання й охолодження пластинного чіпа – також технічний виклик, для CS-3 розробили спеціальну систему рідинного охолодження.
Зі швидким виходом на IPO компаній OpenAI, Anthropic, SpaceX та інших AI-компаній, галузь AI-чіпів стає центром уваги капітальних ринків. Cerebras як перша публічна AI-чіп-компанія на Nasdaq дала подальшим компаніям позитивний старт — перший день +89%.
Та конкуренція на ринку AI-чіпів лише зростає — окрім Nvidia, AMD, Intel та багато стартапів пропонують нові продукти. Чи зможе рішення — чіп на всю пластину — Cerebras закріпитися на основному ринку AI-тренувань, покаже час і кількість нових замовників.
Відмова від відповідальності: зміст цієї статті відображає виключно думку автора і не представляє платформу в будь-якій якості. Ця стаття не повинна бути орієнтиром під час прийняття інвестиційних рішень.
Вас також може зацікавити
У тренді
БільшеУстанова: У другому кварталі фундаментальні фактори золота та срібла залишаються стабільними, у короткостроковій перспективі очікується коливання, чекаємо сигналу для початку трендового ринку
Індекси акцій стрімко зростають, зростання зосереджене; ринок облігацій вже "подав сигнал тривоги", Goldman Sachs попереджає: "високі процентні ставки можуть знищити американський фондовий ринок"